Dunia Natural Language Processing (NLP) telah mengalami pergeseran paradigma yang fundamental sejak diperkenalkannya arsitektur Transformer pada tahun 2017. Sebelum era ini, dominasi model urutan (sequence modeling) dipegang erat oleh Recurrent Neural Networks (RNN) dan variannya seperti LSTM (Long Short-Term Memory). Namun, keterbatasan inheren dalam pemrosesan sekuensial dan masalah vanishing gradient mendorong lahirnya inovasi yang mengandalkan mekanisme atensi sepenuhnya. Artikel ini akan membedah secara mendalam struktur, fungsi, dan implementasi model Transformer dalam konteks tugas sequence-to-sequence (seq2seq), serta bagaimana teknologi ini menjadi fondasi bagi model bahasa besar (LLM) modern.
Evolusi Pemodelan Urutan: Dari RNN ke Mekanisme Atensi
Sejarah pemodelan seq2seq awalnya didominasi oleh arsitektur yang memproses data secara bertahap, satu per satu. Model seperti RNN, LSTM, dan GRU (Gated Recurrent Units) bekerja dengan mempertahankan hidden state sebagai bentuk memori dari input sebelumnya. Meskipun efektif untuk urutan pendek, sifat sekuensial ini menciptakan dua hambatan besar: ketidakmampuan untuk melakukan paralelisasi selama pelatihan dan kesulitan dalam menangkap dependensi jarak jauh (long-range dependencies).
Masalah ini mulai teratasi dengan penambahan mekanisme atensi pada tahun 2015, yang memungkinkan dekoder untuk "melihat kembali" pada hidden states enkoder. Namun, terobosan sesungguhnya terjadi melalui makalah "Attention Is All You Need" (2017) yang mengusulkan arsitektur Transformer. Berbeda dengan model sebelumnya, Transformer tidak menggunakan RNN atau konvolusi, melainkan sepenuhnya mengandalkan self-attention [Analytics Vidhya, 2024]. Dengan menghilangkan rekurensi, Transformer memungkinkan paralelisasi masif karena semua kata dalam suatu urutan diproses secara bersamaan.
Transisi dari RNN ke Transformer merepresentasikan pergeseran dari pemrosesan temporal ke pemrosesan spasial atau relasional. Jika RNN mencoba "mengingat" masa lalu melalui hidden state yang terkompresi, Transformer "menghadiri" (attend) seluruh urutan secara sekaligus. Hal ini menyelesaikan masalah fragmentasi konteks yang sering terjadi pada model lama, memberikan fondasi yang dapat diskalakan untuk tugas-tugas kompleks [Analytics Vidhya, 2025].
Arsitektur Inti: Kerangka Kerja Encoder-Decoder
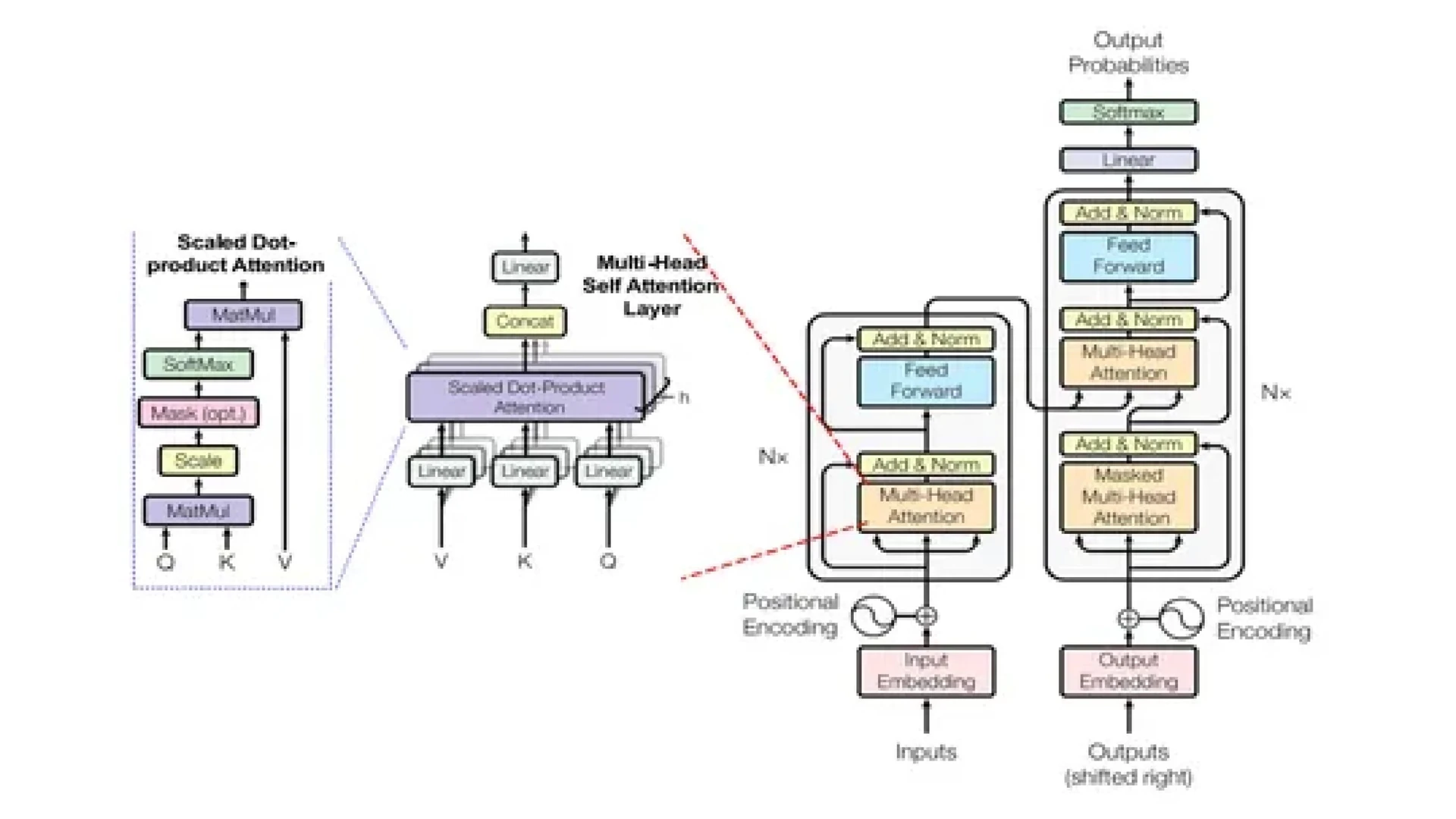
Model Transformer standar dibangun di atas kerangka kerja Encoder-Decoder. Tugas enkoder adalah memetakan urutan input representasi simbol $(x_1, ..., x_n)$ menjadi urutan representasi kontinu $z = (z_1, ..., z_n)$. Berdasarkan representasi $z$ tersebut, dekoder kemudian menghasilkan urutan output $(y_1, ..., y_m)$ satu per satu. Pada setiap langkah, model bersifat auto-regressive, yang berarti model mengonsumsi simbol yang dihasilkan sebelumnya sebagai input tambahan saat menghasilkan simbol berikutnya [Aadhi, 2025].
Komponen Utama dalam Stack Transformer:
- Encoder and Decoder Stacks: Baik enkoder maupun dekoder terdiri dari tumpukan $N$ lapisan identik (biasanya $N=6$). Setiap lapisan enkoder memiliki dua sub-lapisan: mekanisme multi-head self-attention dan jaringan saraf feed-forward posisi-bijak (position-wise fully connected). Lapisan dekoder mencakup sub-lapisan ketiga yang melakukan multi-head attention atas output dari tumpukan enkoder.
- Positional Encoding: Karena Transformer tidak memiliki rekurensi atau konvolusi, mereka tidak memiliki pemahaman inheren tentang urutan token. Untuk mengatasi hal ini, Positional Encodings ditambahkan ke dalam input embeddings. Biasanya, fungsi sinusoidal digunakan untuk memastikan model dapat mengenali posisi relatif dan absolut dari token dalam urutan [GeeksforGeeks, 2025].
- Residual Connections dan Layer Normalization: Setiap sub-lapisan di setiap tumpukan dikelilingi oleh koneksi residual ($x + Sublayer(x)$) yang diikuti oleh Layer Normalization. Pengaturan ini sangat krusial untuk menjaga aliran gradien yang stabil dalam jaringan yang dalam.
Sinergi antara representasi komprehensif enkoder dan generasi sadar konteks dekoder adalah mesin utama Transformer. Dengan menggunakan pengkodean posisi dan tumpukan residual yang dalam, arsitektur ini menjaga integritas spasial data sambil memungkinkan ekstraksi fitur berlapis yang diperlukan untuk pemahaman linguistik tingkat tinggi [Analytics Vidhya, 2024].
Mekanisme Multi-Head Self-Attention: Jantung dari Transformer
Inti dari efektivitas Transformer terletak pada Scaled Dot-Product Attention. Mekanisme ini beroperasi pada tiga vektor utama: Query (Q), Key (K), dan Value (V). Untuk setiap input, model menghitung skor yang mewakili hubungan antara query dan key, yang kemudian digunakan untuk membobot value.
Secara matematis, output atensi dihitung sebagai berikut:
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
Di mana $d_k$ adalah dimensi dari keys. Faktor skala $\frac{1}{\sqrt{d_k}}$ sangat penting untuk mencegah produk titik tumbuh terlalu besar, yang dapat mendorong fungsi softmax ke wilayah dengan gradien yang sangat kecil, sehingga menghambat proses pembelajaran [GeeksforGeeks, 2025].
Multi-Head Attention memperluas konsep ini dengan menjalankan fungsi atensi secara paralel di $h$ "kepala" (heads) yang berbeda. Setiap kepala mempelajari ruang bagian representasi yang berbeda, memungkinkan model untuk secara simultan memperhatikan informasi dari posisi dan aspek semantik yang berbeda (misalnya, satu kepala fokus pada sintaksis sementara yang lain fokus pada koreferensi). Output dari kepala-kepala ini kemudian digabungkan dan diproyeksikan secara linier untuk menghasilkan output akhir [Analytics Vidhya, 2025].
Mekanisme ini memberikan Transformer kemampuan untuk "sadar secara sosial" terhadap seluruh kalimat. Dengan membagi atensi menjadi beberapa kepala, model menghindari jebakan rata-rata hubungan. Sebaliknya, ia mempertahankan beberapa "aliran pemikiran" independen, memungkinkannya menangkap sifat bahasa yang multifaset—di mana satu kata dapat memiliki makna gramatikal, kontekstual, dan simbolis secara bersamaan [Avinash, 2024].
Mekanisme Dekoding: Autoregresi dan Masked Attention
Dalam model seq2seq, dekoder bertanggung jawab untuk menghasilkan urutan target token demi token. Berbeda dengan enkoder yang memproses seluruh input secara bersamaan, dekoder secara inheren bersifat autoregresif. Ini berarti pada setiap langkah waktu $t$, dekoder menggunakan token yang dihasilkan sebelumnya ${y_1, ..., y_{t-1}}$ sebagai bagian dari input untuk memprediksi token berikutnya $y_t$ [Analytics Vidhya, 2024].
Untuk menjaga integritas properti autoregresif selama pelatihan, Transformer menggunakan Masked Multi-Head Attention. Tanpa masking, model dapat dengan mudah "melihat ke depan" pada kata berikutnya dalam urutan yang disediakan selama pelatihan, yang tidak mungkin dilakukan saat inferensi. Mask biasanya berupa matriks segitiga bawah yang diisi dengan $-\infty$ pada posisi masa depan, secara efektif menihilkan bobot atensi untuk token apa pun yang muncul kemudian dalam urutan [Kuyucu, 2023].
Dekoder juga memiliki sub-lapisan atensi kedua: Encoder-Decoder Attention. Di sini, vektor Query (Q) berasal dari lapisan dekoder sebelumnya, sementara vektor Key (K) dan Value (V) bersumber langsung dari representasi output akhir enkoder. Hal ini memungkinkan dekoder untuk melakukan "referensi silang" terhadap kalimat input asli di setiap langkah proses generasi, memastikan bahwa output tetap berakar secara kontekstual pada materi sumber [Aadhi, 2025].
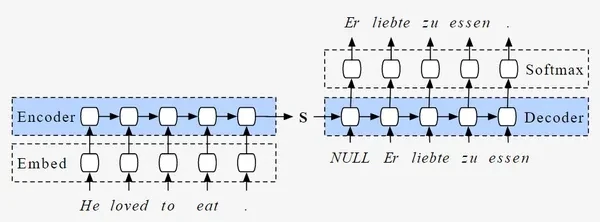
Mengatasi Hambatan Kompresi dengan Representasi Dimensi Tinggi
Model seq2seq tradisional, seperti yang dibangun dengan LSTM atau GRU, sangat bergantung pada satu Context Vector—sebuah hidden state dengan panjang tetap yang bertindak sebagai jembatan antara enkoder dan dekoder. Arsitektur ini menderita masalah "bottleneck": enkoder harus mengompresi kalimat dengan panjang variabel menjadi satu vektor tunggal (misalnya, 512 dimensi). Seiring bertambahnya panjang kalimat, kesetiaan kompresi ini menurun, yang menyebabkan skor evaluasi seperti BLEU menjadi lebih rendah [Analytics Vidhya, 2024].
Transformer modern memecahkan masalah ini dengan meneruskan seluruh tumpukan vektor output enkoder ke dekoder. Alih-alih satu jembatan tunggal, dekoder memiliki akses ke representasi dimensi tinggi yang kaya dari setiap token dalam urutan input. Ini menghilangkan hambatan dan memungkinkan dekoder untuk fokus pada token input tertentu secara dinamis menggunakan mekanisme atensi [Aadhi, 2025].
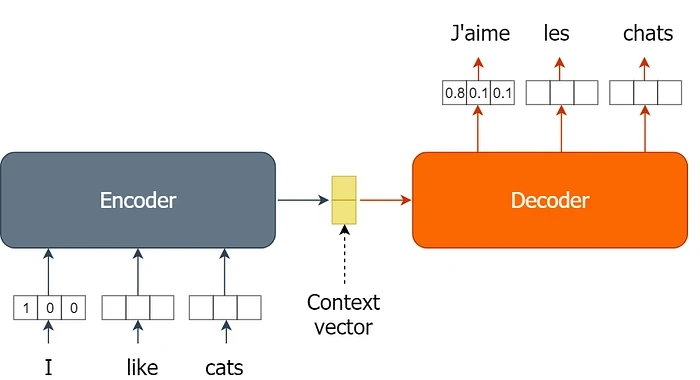
Evolusi dari satu vektor konteks ke antarmuka berbasis atensi merepresentasikan lompatan besar dalam kepadatan informasi. Dengan membiarkan dekoder menanyakan output enkoder secara selektif, Transformer mempertahankan kinerja tinggi bahkan pada dokumen yang sangat panjang, yang merupakan persyaratan kritis untuk tugas-tugas seperti ringkasan dokumen dan penerjemahan teks panjang.
Strategi Optimalisasi: Teacher Forcing dan Fungsi Kerugian
Melatih model seq2seq sangat intensif secara komputasi dan memerlukan strategi khusus untuk menangani "exposure problem". Masalah ini terjadi jika dekoder membuat kesalahan di awal urutan; jika model menggunakan prediksinya sendiri yang salah sebagai input untuk langkah berikutnya, kesalahan tersebut akan menumpuk, dan model akan memasuki keadaan yang tidak pernah dilihatnya selama pelatihan.
Untuk memitigasi hal ini, peneliti menggunakan teknik Teacher Forcing. Selama pelatihan, alih-alih memasukkan prediksi model sendiri yang berpotensi salah $y_{t-1}$ ke langkah berikutnya, kita memasukkan token ground truth dari data pelatihan. Ini menjaga model tetap pada "jalur yang benar". Namun, seiring kemajuan pelatihan, teacher forcing sering dikurangi secara bertahap sehingga model dapat belajar pulih dari kesalahannya sendiri [Analytics Vidhya, 2024].
Selain itu, fungsi kerugian yang umum digunakan adalah Cross-Entropy Loss, yang mengukur perbedaan antara distribusi probabilitas yang diprediksi atas kosakata dan distribusi aktual. Optimasi biasanya dilakukan menggunakan algoritma Adam, yang memanfaatkan laju pembelajaran adaptif dan momentum untuk menavigasi lanskap kerugian yang kompleks dari tumpukan atensi yang dalam [Analytics Vidhya, 2024].
Tugas Lanjutan dan Metrik Evaluasi
Arsitektur Transformer telah bercabang menjadi model khusus seperti BART (Bidirectional and Auto-Regressive Transformers) dan T5 (Text-to-Text Transfer Transformer). Model-model ini sangat efektif untuk Abstractive Summarization, di mana model tidak hanya mengekstrak kalimat tetapi menulis ulang informasi dengan cara yang ringkas dan menyerupai gaya manusia [Bhat, 2025].
Evaluasi terhadap model-model ini memerlukan metrik yang melampaui akurasi sederhana:
* BLEU (Bilingual Evaluation Understudy): Terutama digunakan untuk penerjemahan, metrik ini mengukur tumpang tindih n-gram antara output model dan referensi manusia.
* ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Terutama digunakan untuk ringkasan, metrik ini berfokus pada recall, memastikan bahwa ringkasan menangkap informasi kunci dari sumber.
* Perplexity: Ukuran seberapa baik distribusi probabilitas memprediksi sampel, digunakan terutama untuk pemodelan bahasa.
Tujuan akhir dari arsitektur canggih dan metrik evaluasi ini adalah untuk bergerak melampaui penerjemahan "mekanis" menuju pemahaman "semantik". Baik tugasnya adalah menerjemahkan bahasa atau meringkas laporan panjang, logika dasar Transformer memastikan bahwa output tidak hanya benar secara gramatikal, tetapi juga setia secara kontekstual dan semantik terhadap sumbernya.
Kesimpulan
Model Transformer telah merevolusi cara kita memproses dan menghasilkan bahasa alami. Dengan menggantikan rekurensi sekuensial dengan mekanisme self-attention yang paralel dan kuat, Transformer mampu menangani dependensi jarak jauh dengan efisiensi yang belum pernah ada sebelumnya. Melalui arsitektur enkoder-dekoder, penggunaan masked attention, dan strategi pelatihan seperti teacher forcing, model ini telah menetapkan standar baru dalam berbagai tugas seq2seq. Seiring dengan terus berkembangnya ekosistem seperti Hugging Face dan munculnya arsitektur yang lebih efisien, fondasi yang diletakkan oleh Transformer akan terus menjadi pendorong utama inovasi dalam kecerdasan buatan di masa depan.
Referensi
Aadhi, A. (2025). Encoder- Decoder Architecture : Fulcrum of Transformers. Diakses dari https://medium.com/@aadhitya98/encoder-decoder-architecture-fulcrum-of-transformers-736da068d2ac
Analytics Vidhya. (2025). How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models. Diakses dari https://www.analyticsvidhya.com/blog/2019/06/understanding-transformers-nlp-state-of-the-art-models/
Analytics Vidhya. (2024). Understanding Transformers: A Deep Dive into NLP's Core Technology. Diakses dari https://www.analyticsvidhya.com/blog/2024/04/understanding-transformers-a-deep-dive-into-nlps-core-technology/
Analytics Vidhya. (2025). Understanding Attention Mechanisms Using Multi-Head Attention. Diakses dari https://www.analyticsvidhya.com/blog/2023/06/understanding-attention-mechanisms-using-multi-head-attention/
Analytics Vidhya. (2024). Sequence-to-Sequence Models for Language Translation. Diakses dari https://www.analyticsvidhya.com/blog/2024/05/sequence-to-sequence-models-for-language-translation/
Avinash. (2024). Transformer model and self attentions mechanisms in NLP. Diakses dari https://medium.com/@avinashmachinelearninginfo/transformer-model-and-self-attentions-mechanisms-in-nlp-ab2f0778d2a1
Bhat, P. (2025). Building a Text Summarizer with Transformers (BART/T5). Diakses dari https://medium.com/data-science-collective/building-a-text-summarizer-with-transformers-bart-t5-f5bfa0d6ee11
GeeksforGeeks. (2025). Transformer Attention Mechanism in NLP. Diakses dari https://www.geeksforgeeks.org/nlp/transformer-attention-mechanism-in-nlp/
Hugging Face. (2024). Total noob’s intro to Hugging Face Transformers. Diakses dari https://huggingface.co/blog/noob_intro_transformers
Kuyucu, A. K. (2023). LLM Tutorial 4 — The Transformer Model and Self-Attention. Diakses dari https://medium.com/ai-in-plain-english/llm-tutorial-4-the-transformer-model-and-self-attention-a6b111fe9fa4