Halo semuanya! Pernah nggak sih kamu merasa bangga banget karena model machine learning yang kamu latih dapet akurasi 99% di laptop kamu? Rasanya pengen langsung selebrasi, kan? Tapi tunggu dulu! Sebelum kamu buru-buru men-deploy model itu ke sistem produksi, ada satu pertanyaan krusial yang harus kamu jawab: Apakah model kamu beneran pintar, atau dia cuma hafal data latihannya aja?
Inilah mimpi buruk setiap praktisi data: Overfitting. Di artikel kali ini, kita bakal kupas tuntas kenapa akurasi tinggi di tahap training itu seringkali menipu, dan gimana teknik sakti bernama Cross-Validation bisa jadi penyelamat kamu. Kita bakal belajar dari dasar banget, mulai dari konsep burung dara sampai kodingan praktis pake Scikit-Learn. Yuk, kencangkan sabuk pengaman kita!
Mimpi Buruk Bernama Overfitting dan Underfitting
Di dunia machine learning, tujuan utama kita bukan cuma bikin model yang jago jawab soal yang udah pernah dia liat, tapi model yang mampu melakukan generalization—alias jago nebak data baru yang belum pernah dia sentuh sama sekali. Nah, di sinilah muncul dua musuh bebuyutan: Overfitting dan Underfitting.
Fenomena overfitting dan underfitting merupakan dua sisi mata uang dalam optimasi model machine learning. Menurut Antrakasa, overfitting muncul ketika model belajar terlalu detail hingga menyesuaikan diri dengan noise atau fluktuasi acak yang tidak relevan. Dampaknya, performa model akan tampak luar biasa pada data latihan namun merosot tajam saat diuji pada data validasi. Sebaliknya, underfitting mencerminkan kondisi di mana model gagal menangkap hubungan dasar antara fitur dan target, biasanya karena arsitektur yang terlalu sederhana atau durasi pelatihan yang kurang.
Dalam machine learning, penyebab utama overfitting meliputi:
1. Kompleksitas Model: Penggunaan parameter yang berlebihan (seperti polinomial derajat tinggi untuk data linear).
2. Kurangnya Data: Dataset kecil membuat model mudah menghafal contoh spesifik alih-alih belajar pola umum.
3. Noise dalam Data: Kesalahan atau variansi acak dalam data latihan dianggap sebagai pola signifikan oleh model.
Deteksi Dini dan Keseimbangan Bias-Variance
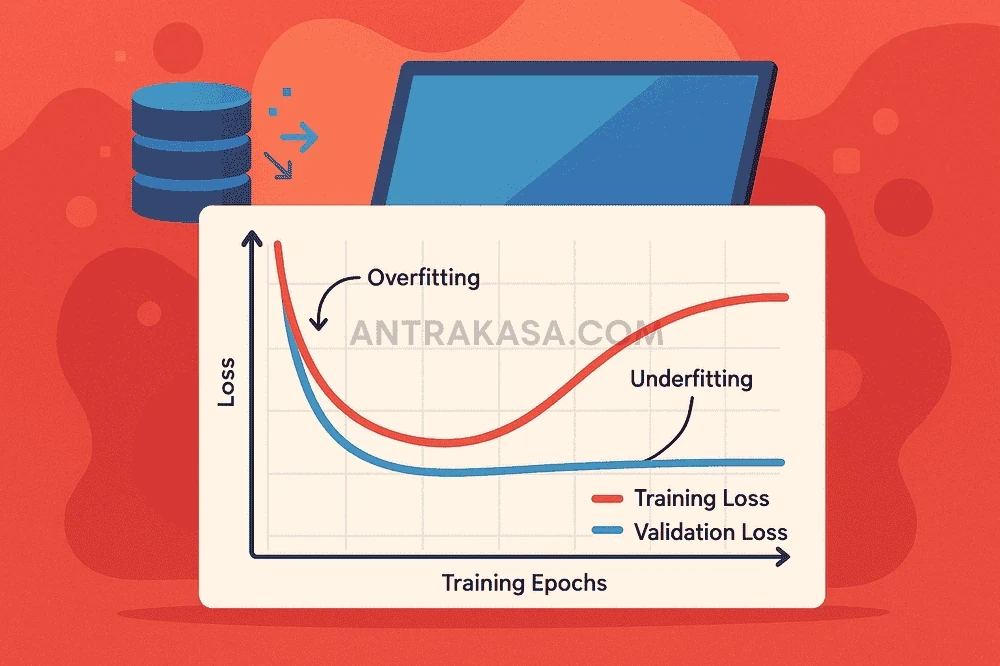
Deteksi overfitting dilakukan dengan memantau kurva loss selama pelatihan. Tanda yang paling jelas adalah ketika training loss terus menurun, namun validation loss mulai meningkat setelah titik tertentu. Kondisi ini menunjukkan bahwa model mulai kehilangan kemampuan generalisasinya. Antrakasa menyarankan penggunaan teknik early stopping—menghentikan pelatihan tepat sebelum validation loss mulai naik—sebagai salah satu solusi preventif yang paling efektif.
Memahami overfitting dan underfitting adalah tentang menemukan titik keseimbangan antara bias dan variansi. Model yang ideal harus memiliki bias yang cukup rendah untuk menangkap pola, namun variansi yang juga rendah agar tidak sensitif terhadap perubahan kecil pada dataset. Tanpa evaluasi yang ketat, model yang di-deploy ke dunia nyata berisiko memberikan prediksi yang menyesatkan bagi pengguna.
Strategi Pemisahan Data: Train-Test-Validation Split
Pemisahan data yang tepat adalah langkah kritis pertama untuk mencegah kebocoran data (data leakage). Analytics Vidhya menekankan pentingnya pembagian dataset menjadi tiga subset utama: Training, Validation, dan Testing, yang masing-masing memiliki peran yang sangat spesifik.
Peran Masing-masing Subset
- Training Set: Digunakan oleh model untuk belajar mengenali pola-pola dasar dalam data. Di sinilah model menyesuaikan weights dan parameters-nya.
- Validation Set: Bertindak sebagai "checkpoint" selama proses pengembangan. Subset ini digunakan untuk melacak parameter model (hyperparameter tuning) dan mendeteksi apakah model mulai mengalami overfitting. Kamu bisa mencoba berbagai nilai learning rate atau arsitektur di sini.
- Testing Set: Merupakan ujian akhir model pada skenario dunia nyata. Data ini tidak boleh disentuh selama proses pelatihan atau tuning agar hasil evaluasi tetap objektif.
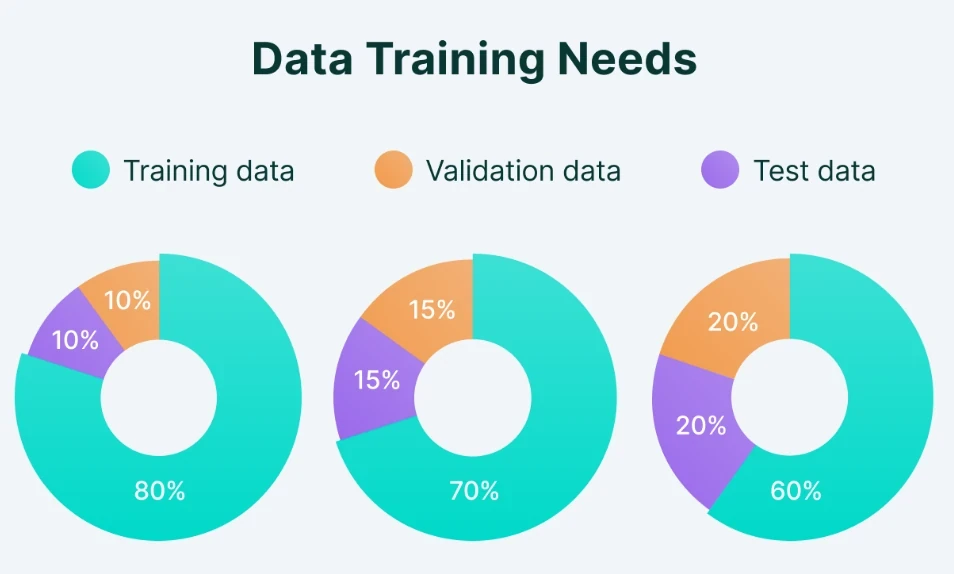
Rasio Pembagian dan Best Practices
Rasio umum yang digunakan adalah 70/15/15 atau 80/10/10. Namun, faktor yang lebih penting adalah randomization (pengacakan data) dan stratification (menjaga distribusi kelas agar seimbang di setiap split). Kegagalan dalam melakukan stratifikasi pada kasus klasifikasi yang tidak seimbang (imbalanced class) dapat menyebabkan model tampak akurat padahal sebenarnya ia hanya "menebak" kelas mayoritas.
Kedisiplinan untuk tidak membiarkan informasi dari test set mempengaruhi proses training (data leakage) adalah kunci keberhasilan prediksi analytics. Dengan menggunakan validation set secara aktif, pengembang dapat melakukan iterasi model dengan lebih aman dan terukur.
Teknik Validasi: Train/Test Split vs Cross-Validation
Untuk mengatasi risiko overfitting, praktisi data menggunakan berbagai metode pembagian data. Ichi.pro menjelaskan bahwa metode paling dasar adalah Train/Test Split, di mana dataset dibagi menjadi dua bagian: satu untuk melatih model dan satu lagi untuk menguji kinerjanya secara independen.
Implementasi Dasar dan Kelemahannya
Dalam ekosistem Python, libraryScikit-Learn menyediakan fungsi seperti train_test_split untuk melakukan pembagian ini secara otomatis. Misalnya, dengan menyisihkan 20% data sebagai test set, kita dapat mensimulasikan bagaimana model akan berhadapan dengan data umum. Namun, pembagian tunggal ini memiliki kelemahan: hasil evaluasi sangat bergantung pada bagaimana data tersebut dibagi secara acak. Kamu bisa saja "beruntung" mendapatkan split data yang mudah diprediksi, atau sebaliknya.
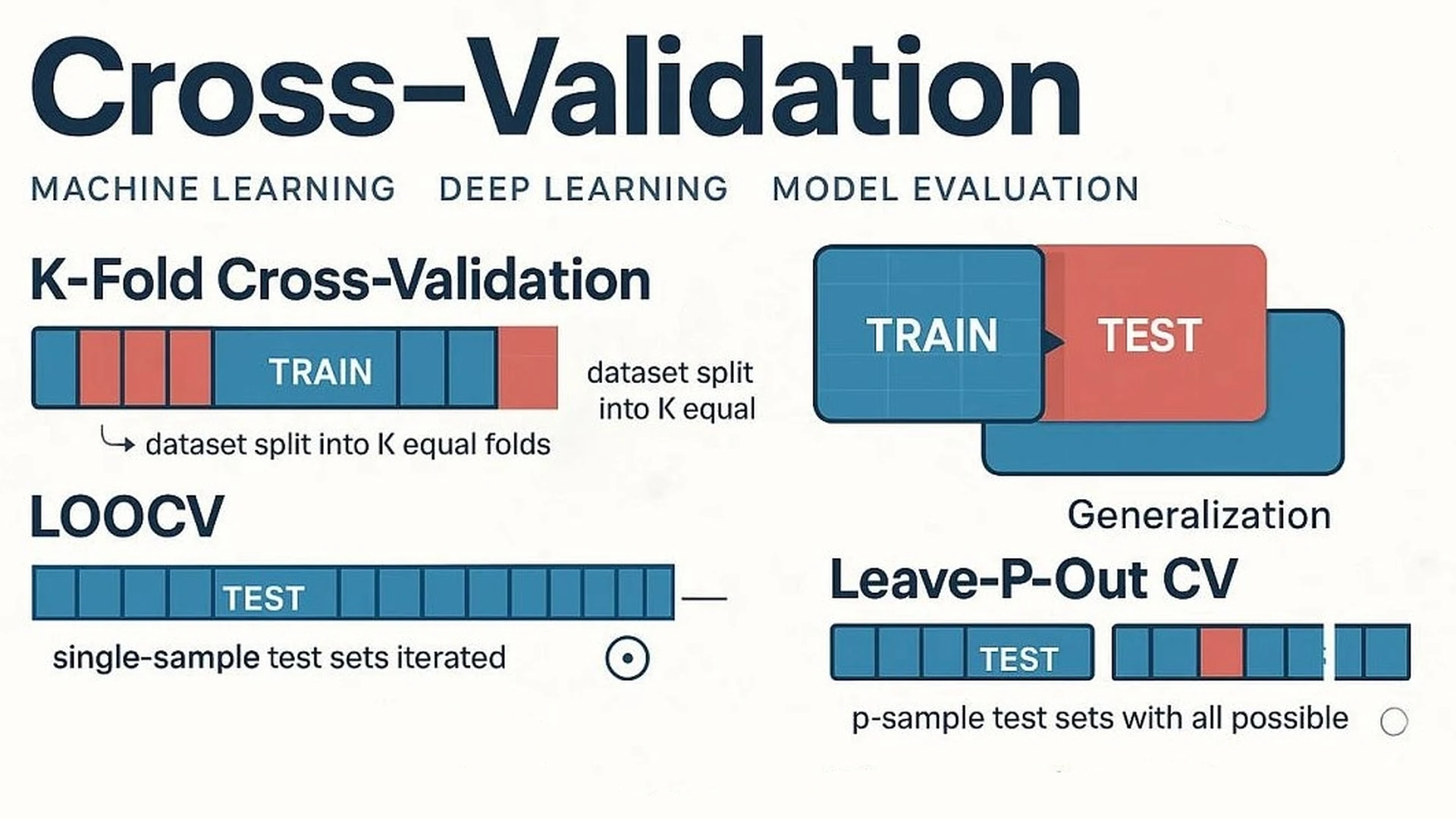
Keunggulan K-Fold Cross-Validation
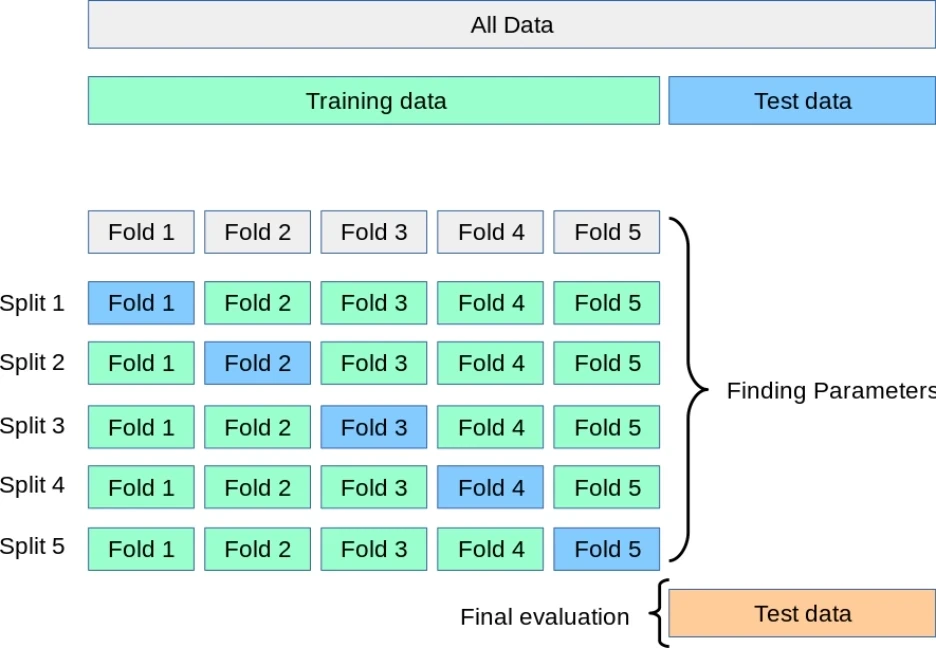
Teknik yang lebih robust adalah K-Fold Cross-Validation. Data dibagi menjadi k subset (fold). Model dilatih pada k-1 bagian dan diuji pada bagian yang tersisa. Proses ini diulang sebanyak k kali sehingga setiap titik data pernah menjadi data uji. Rata-rata performa dari semua iterasi ini memberikan estimasi akurasi yang lebih stabil dan tidak bias. Dibimbing.id menekankan bahwa metode ini memastikan performa model tidak dipengaruhi oleh pemilihan subset data tertentu.

Ada juga metode Leave One Out Cross Validation (LOOCV), di mana jumlah fold sama dengan jumlah observasi. Meskipun mengurangi bias secara signifikan, metode ini sangat mahal secara komputasi dan biasanya hanya disarankan untuk dataset berukuran kecil. Untuk dataset besar, nilai k=5 atau k=10 dianggap sebagai standar industri yang memberikan trade-off terbaik antara akurasi dan efisiensi waktu.
Tutorial Implementasi K-Fold dengan Scikit-Learn
Mari kita langsung praktek! Kita akan menggunakan Scikit-Learn untuk membandingkan performa model dengan teknik Cross-Validation yang berbeda.
import numpy as np
from sklearn.model_selection import train_test_split, KFold, RepeatedKFold, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 1. Persiapan Data
data = load_iris()
X, y = data.data, data.target
# 2. Definisi Model
# Kita gunakan RandomForestClassifier yang merupakan salah satu Ensemble Method populer
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 3. Strategi Validasi: K-Fold Dasar (5 Folds)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
scores_kf = cross_val_score(model, X, y, cv=kf)
print(f"K-Fold Scores: {scores_kf}")
print(f"Mean Accuracy: {scores_kf.mean():.4f}")
print(f"Std Dev: {scores_kf.std():.4f}")
# 4. Strategi Lanjutan: Repeated K-Fold (10 splits, 3 repeats)
rkf = RepeatedKFold(n_splits=10, n_repeats=3, random_state=42)
scores_rkf = cross_val_score(model, X, y, cv=rkf)
print(f"\nRepeated K-Fold Mean Accuracy: {scores_rkf.mean():.4f}")
print(f"Repeated K-Fold Std Dev: {scores_rkf.std():.4f}")
Bedah Teknis: Apa yang Terjadi di Balik Layar?
Di blok kode pertama, kita menggunakan KFold dengan n_splits=5. Ini membagi data iris (150 sampel) menjadi 5 bagian yang masing-masing berisi 30 sampel. Fungsi cross_val_score kemudian menjalankan 5 siklus pelatihan dan pengujian secara otomatis. Hasilnya adalah array berisi 5 skor akurasi. Menghitung rata-rata dan standard deviation (Std Dev) sangat penting untuk melihat seberapa stabil model kamu.
Pada bagian kedua, kita naik level menggunakan RepeatedKFold. Mengapa? Karena seringkali satu kali proses k-fold menghasilkan estimasi yang "noisy". Dengan n_repeats=3, kita mengulangi seluruh proses 10-fold sebanyak tiga kali dengan pengacakan yang berbeda. Totalnya ada 30 evaluasi! Machine Learning Mastery menjelaskan bahwa pendekatan ini memberikan estimasi yang jauh lebih akurat mengenai performa model yang sebenarnya karena mengurangi variansi estimasi. Ini adalah standar emas bagi praktisi yang menginginkan keyakinan tinggi pada model mereka.
Tantangan Khusus: Time Series Cross-Validation
Data deret waktu (time series) memiliki karakteristik unik di mana urutan kronologis sangatlah penting. Menggunakan k-fold tradisional yang mengacak data akan menyebabkan data leakage, di mana model seolah-olah "melihat masa depan" saat memprediksi masa lalu.
Walk-Forward Validation
Analytics Vidhya menjelaskan teknik TimeSeriesSplit atau Walk-Forward Validation. Dalam metode ini, data diuji secara berurutan. Misalnya, model dilatih pada data bulan Januari untuk memprediksi Februari, kemudian dilatih pada Januari-Februari untuk memprediksi Maret, dan seterusnya. Hal ini menjaga integritas temporal dan mensimulasikan penggunaan model di dunia nyata secara akurat.
Tantangan dalam data deret waktu meliputi non-stationarity (perubahan pola seiring waktu) dan keterbatasan data pada fold awal. Untuk mengatasinya, pemilihan ukuran jendela (window size) yang tepat dan monitoring terhadap kesalahan prediksi di setiap fold sangatlah krusial.
Teknik Lanjutan Menghindari Overfitting
Selain validasi silang, menghindari overfitting membutuhkan pendekatan multi-dimensi. Aihub.id merangkum beberapa teknik mutakhir yang digunakan saat ini:
- Data Augmentation: Sangat populer dalam komputer visi, teknik ini menciptakan variasi data baru secara artifisial (seperti memutar, menggeser, atau mengubah warna gambar). Hal ini memaksa model untuk belajar fitur yang lebih robust.
- Feature Selection: Terlalu banyak fitur yang tidak relevan dapat membingungkan model. Proses pemilihan fitur yang paling berkontribusi (menggunakan analisis korelasi atau RFE) membantu menyederhanakan model.
- Regularisasi (L1/L2): Menambahkan penalti pada bobot model yang terlalu besar, sehingga mencegah model menjadi terlalu fleksibel. L1 (Lasso) bisa membuat bobot jadi nol (sekaligus feature selection), sedangkan L2 (Ridge) mengecilkan bobot tanpa membuatnya nol.
- Dropout: Khusus untuk Neural Networks, teknik ini secara acak "mematikan" neuron selama pelatihan untuk mencegah ketergantungan pada jalur spesifik.
- Metode Ensemble: Menggabungkan prediksi dari beberapa model (seperti Random Forest atau XGBoost). Bagging mengurangi variansi, sementara Boosting mengurangi bias.

Paradoks Overfitting: Fenomena Double Descent
Menariknya, penelitian terbaru mengenai Double Descent menunjukkan bahwa pada model yang sangat besar (seperti LLM), performa bisa membaik kembali setelah melewati fase overfitting yang parah. Ini menantang pemahaman tradisional kita (Bias-Variance Trade-off) di mana model yang terlalu kompleks pasti akan gagal.
Namun, bagi sebagian besar aplikasi praktis sehari-hari, prinsip-prinsip validasi silang dan regularisasi tetap menjadi panduan utama. Double descent adalah fenomena unik dalam deep learning yang sangat besar yang membuka ruang bagi riset masa depan mengenai kapasitas model.
Kesimpulan
Membangun model machine learning yang sakti butuh disiplin tinggi dalam evaluasi. Mulai dari pemisahan data yang ketat (Train-Test-Validation), penerapan Cross-Validation yang tepat (K-Fold, Repeated, atau Time Series), hingga penggunaan teknik Regularisasi dan Ensemble.
Referensi
Antrakasa. (2024). Cara Mengatasi Overfitting dan Underfitting. Retrieved from https://www.antrakasa.com/cara-mengatasi-overfitting-dan-underfitting/
Analytics Vidhya. (2026). Time Series Cross-Validation: Techniques & Implementation. Retrieved from https://www.analyticsvidhya.com/blog/2026/03/time-series-cross-validation/
Analytics Vidhya. (2026). Train-Test-Validation Split: A Critical Component of ML. Retrieved from https://www.analyticsvidhya.com/blog/2023/11/train-test-validation-split/
Cloudcomputing.id / Aihub.id. (2025). Apa Itu Overfitting? Bahaya, Cara Deteksi, dan Solusinya. Retrieved from https://event.cloudcomputing.id/pengetahuan-dasar/apa-itu-overfitting
Dibimbing.id. (2024). Apa Itu Overfitting? Penyebab, Contoh, dan Cara Deteksinya. Retrieved from https://dibimbing.id/blog/detail/apa-itu-overfitting-penyebab-contoh-dan-cara-deteksinya
Hugging Face. (2022). Model Cards. Retrieved from https://huggingface.co/blog/model-cards
Ichi.pro. (2024). Train / Test Split dan Cross Validation dengan Python. Retrieved from https://ichi.pro/id/train-test-split-dan-cross-validation-dengan-python-141519640896694
MachineLearningMastery.com. (2020). Repeated k-Fold Cross-Validation for Model Evaluation in Python. Retrieved from https://machinelearningmastery.com/repeated-k-fold-cross-validation-with-python/
Kaggle. (2024). Cross-validation with Linear Regression. Retrieved from https://www.kaggle.com/code/jnikhilsai/cross-validation-with-linear-regression