
Pernahkah kamu membayangkan bagaimana sebuah model AI, seperti ChatGPT atau sistem pengenal wajah di ponselmu, bisa "belajar"? Inti dari proses pembelajaran tersebut adalah sebuah masalah optimasi yang sangat kompleks. Bayangkan kamu berada di puncak gunung yang diselimuti kabut tebal, dan tugasmu adalah menemukan titik terendah di lembah (global minimum) hanya dengan merasakan kemiringan tanah di bawah kakimu. Inilah yang dilakukan oleh algoritma optimasi dalam deep learning.
Dahulu, kita mengandalkan metode klasik seperti Stochastic Gradient Descent (SGD). Namun, seiring dengan arsitektur jaringan saraf yang semakin dalam dan rumit, SGD mulai menemui batasannya. Di sinilah Adaptive Moment Estimation, atau yang lebih kita kenal sebagai Adam, muncul sebagai pahlawan. Adam bukan sekadar algoritma biasa; ia adalah perpaduan jenius antara kecepatan dan stabilitas. Dalam panduan ini, kita akan membedah Adam habis-habisan, mulai dari konsep dasarnya hingga kita bisa membangunnya sendiri menggunakan NumPy. Siap untuk masuk ke dalam "otak" optimasi AI? Mari kita mulai!
Evolusi Optimasi: Dari SGD Menuju Adam
Sebelum kita memuja Adam, kita harus mengerti dulu masalah apa yang ia selesaikan. Algoritma paling dasar, Stochastic Gradient Descent (SGD), mengupdate parameter model berdasarkan gradien dari fungsi loss terhadap satu contoh data atau mini-batch. Meskipun efisien secara komputasi, SGD punya masalah besar: osilasi yang liar. Bayangkan bola yang memantul ke kiri dan ke kanan saat menuruni lembah sempit, alih-alih meluncur lurus ke bawah.
Selain itu, SGD menggunakan satu learning rate global untuk semua parameter. Masalahnya, tidak semua parameter itu sama! Ada berat (weight) yang perlu berubah cepat, ada juga yang butuh langkah kecil agar tidak meleset. Munculah RMSprop (Root Mean Square Propagation) yang mencoba menormalkan update gradien dengan menyimpan rata-rata bergerak dari kuadrat gradien. Ini membantu meredam osilasi di arah yang curam dan mempercepat gerakan di daerah yang landai. Namun, RMSprop masih kurang satu komponen penting: "momentum".
Adam hadir sebagai solusi "best of both worlds". Ia menggabungkan keunggulan Momentum (yang membantu navigasi di area lokal minimum dan saddle points) dengan kemampuan adaptif RMSprop. Itulah mengapa Adam disebut sebagai adaptive moment estimation—ia mengestimasi momen pertama (rata-rata) dan momen kedua (varians) dari gradien secara adaptif.
Kenapa Adam Begitu Spesial?
- Adaptive Learning Rates: Adam menghitung learning rate yang berbeda untuk setiap parameter. Jadi, kamu tidak perlu lagi pusing melakukan hyperparameter tuning yang berlebihan.
- Tahan Terhadap Gradien yang Berisik (Sparse Gradients): Adam bekerja sangat baik pada masalah dengan data yang tidak merata atau gradien yang sangat fluktuatif, seperti dalam tugas Natural Language Processing (NLP) atau Computer Vision.
- Efisiensi Memori & Komputasi: Walaupun menyimpan dua rata-rata bergerak untuk setiap parameter, Adam tetap ringan dan cocok untuk dataset skala besar.
- Standar Industri: Di dunia riset AI modern, Adam adalah pilihan pertama bagi para engineer sebelum mencoba optimasi lainnya.
Fondasi Matematika: Rahasia di Balik Update Adam
Agar kamu benar-benar paham, kita harus menyentuh sedikit matematikanya. Jangan khawatir, ini tidak serumit yang kamu bayangkan! Adam bekerja dengan empat variabel utama: momen pertama ($m_t$), momen kedua ($v_t$), langkah waktu ($t$), dan tiga hyperparameter ($\beta_1, \beta_2$, dan $\epsilon$).
1. Estimasi Momen (Moment Estimation)
Momen pertama ($m_t$) adalah rata-rata bergerak eksponensial dari gradien masa lalu. Ini merepresentasikan "momentum" atau arah ke mana optimasi harus bergerak.
$$m_t = \beta_1 \cdot m_{t-1} + (1 - \beta_1) \cdot g_t$$
Di mana $g_t$ adalah gradien pada waktu $t$.
Momen kedua ($v_t$) adalah rata-rata bergerak eksponensial dari kuadrat gradien. Ini merepresentasikan besarnya variansi atau magnitudo dari update terbaru.
$$v_t = \beta_2 \cdot v_{t-1} + (1 - \beta_2) \cdot g_t^2$$
2. Koreksi Bias (Bias Correction)
Karena kita menginisialisasi $m_t$ dan $v_t$ dengan angka nol, pada langkah-langkah awal, nilainya akan sangat "tertarik" ke arah nol (bias). Untuk memperbaikinya, Adam menerapkan koreksi bias:
$$\hat{m}_t = \frac{m_t}{1 - \beta_1^t}$$
$$\hat{v}_t = \frac{v_t}{1 - \beta_2^t}$$
Seiring bertambahnya $t$, nilai $\beta^t$ akan mengecil menuju nol, dan koreksi ini perlahan tidak lagi diperlukan. Namun, di awal training, langkah ini krusial agar model tidak "macet".
3. Update Parameter
Langkah terakhir adalah memperbarui parameter ($w_t$) menggunakan estimasi yang sudah dikoreksi bias tadi, dikalikan dengan learning rate global ($\eta$):
$$w_{t+1} = w_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \cdot \hat{m}_t$$
Kita menambahkan $\epsilon$ (biasanya $10^{-8}$) untuk mencegah pembagian dengan nol. Inilah keajaiban Adam: pembagi $\sqrt{\hat{v}_t}$ memastikan bahwa parameter dengan gradien besar akan mendapatkan langkah yang lebih kecil, dan sebaliknya.
Implementasi Adam dari Nol dengan Python
Sekarang, saatnya kita kotor-kotoran dengan kode! Kita hanya butuh NumPy untuk melakukan operasi vektor ini. Jika kamu bisa membangun ini dari nol, kamu akan punya pemahaman yang jauh lebih dalam dibanding sekadar memanggil torch.optim.Adam.
Tahap 1: Inisialisasi
Sebelum loop training dimulai, kita harus menyiapkan tempat penyimpanan untuk rata-rata bergerak (momen) setiap parameter.
import numpy as np
def initialize_adam(parameters):
"""
Inisialisasi momen pertama dan kedua dengan nol.
"""
L = len(parameters) // 2 # Jumlah layer
v = {} # v akan menyimpan momen pertama (m dalam rumus)
s = {} # s akan menyimpan momen kedua (v dalam rumus)
for l in range(L):
v["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
v["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
s["dW" + str(l+1)] = np.zeros_like(parameters["W" + str(l+1)])
s["db" + str(l+1)] = np.zeros_like(parameters["b" + str(l+1)])
return v, s

Tahap 2: Update Langkah demi Langkah
Di setiap iterasi, setelah kita mendapatkan gradien dari backpropagation, kita terapkan logika Adam. Perhatikan bagaimana $\beta_1$ biasanya diset ke 0.9 dan $\beta_2$ ke 0.999.
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate=0.01,
beta1=0.9, beta2=0.999, epsilon=1e-8):
"""
Update parameter menggunakan algoritma Adam.
"""
L = len(parameters) // 2
v_corrected = {}
s_corrected = {}
for l in range(L):
# 1. Update momen pertama (rata-rata gradien)
v["dW" + str(l+1)] = beta1 * v["dW" + str(l+1)] + (1 - beta1) * grads["dW" + str(l+1)]
v["db" + str(l+1)] = beta1 * v["db" + str(l+1)] + (1 - beta1) * grads["db" + str(l+1)]
# 2. Hitung koreksi bias momen pertama
v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)] / (1 - beta1**t)
v_corrected["db" + str(l+1)] = v["db" + str(l+1)] / (1 - beta1**t)
# 3. Update momen kedua (varians gradien)
s["dW" + str(l+1)] = beta2 * s["dW" + str(l+1)] + (1 - beta2) * (grads["dW" + str(l+1)]**2)
s["db" + str(l+1)] = beta2 * s["db" + str(l+1)] + (1 - beta2) * (grads["db" + str(l+1)]**2)
# 4. Hitung koreksi bias momen kedua
s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)] / (1 - beta2**t)
s_corrected["db" + str(l+1)] = s["db" + str(l+1)] / (1 - beta2**t)
# 5. Update parameter yang sebenarnya
parameters["W" + str(l+1)] -= learning_rate * v_corrected["dW" + str(l+1)] / (np.sqrt(s_corrected["dW" + str(l+1)]) + epsilon)
parameters["b" + str(l+1)] -= learning_rate * v_corrected["db" + str(l+1)] / (np.sqrt(s_corrected["db" + str(l+1)]) + epsilon)
return parameters, v, s
Penjelasan Teknis:
Mengapa kita repot-repot melakukan semua ini? Perhatikan langkah nomor 5. Kita membagi gradien dengan $\sqrt{s_corrected}$. Jika sebuah parameter sering mendapatkan gradien besar, nilai $s$ akan meningkat, sehingga pembaginya besar, dan langkah updatenya jadi lebih kecil (direm). Sebaliknya, parameter yang jarang mendapatkan update akan punya pembagi kecil, sehingga langkahnya lebih besar (digas). Inilah sifat adaptif yang membuat Adam sangat efisien!
Aplikasi Praktis dan Konvergensi
Saat kamu menjalankan Adam pada fungsi objektif (misalnya mencari titik terendah dari sebuah kurva), kamu akan melihat pergerakan yang sangat mulus. Berbeda dengan SGD yang mungkin "zig-zag" atau memantul-mantul, Adam mampu melambat secara otomatis saat mendekati titik optimal. Ini mencegah model "melompati" lembah terdalam hanya karena langkah yang terlalu besar di akhir.
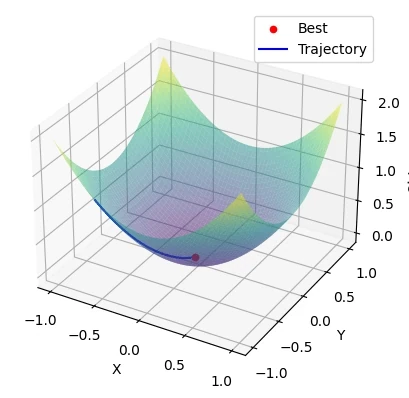
Setelah kita memahami dasar-dasar Adam, penting untuk melihat bagaimana dunia nyata memberikan tantangan baru. Meskipun Adam sangat hebat, ia bukan tanpa cela. Beberapa riset menunjukkan bahwa dalam kondisi tertentu, SGD dengan momentum yang diatur secara manual bisa menghasilkan generalisasi yang sedikit lebih baik pada data baru. Namun, untuk kecepatan dan keandalan di awal proyek, Adam tetap juaranya.
Melangkah Lebih Jauh: AdamW dan Masalah Weight Decay
Seiring berkembangnya AI, para peneliti menemukan masalah menarik: Adam ternyata tidak bekerja dengan baik jika digabungkan dengan L2 Regularization (sering disebut Weight Decay). Pada SGD, kedua hal ini identik. Tapi pada Adam, karena kita melakukan pembagian dengan varians, efek weight decay jadi ikut terdistorsi.
Solusinya? AdamW. Algoritma ini memisahkan (decoupling) langkah weight decay dari langkah update gradien. Jadi, kita mengurangi nilai berat secara langsung setelah melakukan update Adam. Perubahan kecil ini terbukti sangat krusial dalam melatih model raksasa seperti Transformer dan Large Language Models (LLM) yang kita gunakan saat ini.
Masa Depan Optimasi: Mengenal Lion
Jika kamu merasa Adam sudah cukup canggih, tunggu sampai kamu mendengar tentang Lion (EvoLved Sign Momentum). Algoritma ini ditemukan oleh tim Google Brain bukan melalui pemikiran manual manusia, melainkan melalui pencarian algoritma secara otomatis menggunakan komputer!
Lion jauh lebih sederhana dari Adam karena ia hanya menyimpan momen pertama (momentum) dan hanya menggunakan tanda (sign) dari update tersebut. Kelebihannya? Ia menghemat memori hingga 30-50% karena tidak perlu menyimpan momen kedua. Bagi para engineer yang melatih model triliunan parameter pada GPU yang terbatas, ini adalah penghematan yang luar biasa besar.
Kesimpulan: Mana yang Harus Kamu Gunakan?
Memahami Adam dari nol bukan sekadar latihan akademis, melainkan fondasi untuk menjadi AI Engineer yang handal. Kamu sekarang tahu bahwa Adam bukan sihir, melainkan gabungan cerdas dari statistik (momen) dan engineering (adaptif).
Ringkasan untukmu:
- Gunakan Adam sebagai langkah awal untuk hampir semua proyek deep learning.
- Gunakan AdamW jika kamu melatih model besar (seperti Transformer) dan butuh regulerisasi yang kuat.
- Gunakan SGD dengan Momentum jika kamu punya waktu untuk tuning super teliti demi mendapatkan akurasi ekstra di akhir.
- Pantau Lion jika kamu bekerja dengan keterbatasan VRAM GPU yang ketat.
Dunia optimasi AI terus berkembang, tapi dengan menguasai Adam, kamu sudah memegang kunci utama untuk memahami bagaimana mesin belajar dari data. Teruslah bereksperimen, dan jangan takut untuk "mengintip" di bawah kap mesin AI-mu!
Referensi
- bugfree.ai. (2024). Optimization Algorithms: SGD, Adam, and RMSprop Compared. Retrieved from https://bugfree.ai/knowledge-hub/optimization-algorithms-sgd-adam-rmsprop-comparison
- Brownlee, J. (2021). Code Adam Optimization Algorithm From Scratch. MachineLearningMastery.com. Retrieved from https://machinelearningmastery.com/adam-optimization-from-scratch/
- Kingma, D. P., & Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980.
- Loshchilov, I., & Hutter, F. (2019). Decoupled Weight Decay Regularization. ICLR 2019.
- Sitanand. (2025). Modern Optimizers: AdamW, Lion, and What Actually Works at Scale. Retrieved from https://medium.com/@spjosyula2005/modern-optimizers-adamw-lion-and-what-actually-works-at-scale-68ffc033713b