
Selamat datang di era keemasan Artificial Intelligence! Jika kamu sering berselancar di media sosial atau mengelola platform e-commerce, kamu pasti menyadari betapa banyaknya opini yang berseliweran setiap detiknya. Mulai dari ulasan produk yang sangat puas hingga keluhan pelanggan yang berapi-api. Pertanyaannya: bagaimana kita bisa mengolah ribuan—bahkan jutaan—data teks tersebut secara otomatis untuk memahami perasaan (sentimen) di baliknya?
Jawabannya adalah Sentiment Analysis. Dan hari ini, kita tidak hanya akan membahas teorinya saja. Saya akan mengajak kamu melakukan deep dive teknis untuk membangun model sentiment analysis pertama kamu khusus untuk teks Bahasa Indonesia menggunakan library paling populer di dunia AI saat ini: Hugging Face Transformers.
Revolusi NLP: Dari Dense Model ke Efisiensi Modern
Sebelum kita masuk ke kode, penting bagi kita sebagai engineer untuk memahami lanskap teknologi yang kita gunakan. Bidang Natural Language Processing (NLP) telah mengalami transformasi radikal sejak diperkenalkannya arsitektur Transformer. Dulu, kita terbiasa dengan model yang bersifat "dense", di mana setiap parameter dalam model aktif untuk setiap kata (token) yang diproses. Namun, seiring dengan scaling laws yang menuntut model yang lebih besar, pendekatan dense mulai mencapai batas efisiensi komputasinya.
Di sinilah muncul konsep Mixture of Experts (MoE). Bayangkan sebuah tim ahli di mana hanya orang yang paling relevan yang bekerja untuk tugas tertentu. Dalam arsitektur MoE, lapisan feed-forward digantikan oleh sekelompok "experts" (sub-jaringan). Sebuah komponen bernama router akan secara dinamis memilih subset kecil dari pakar ini untuk memproses setiap token.
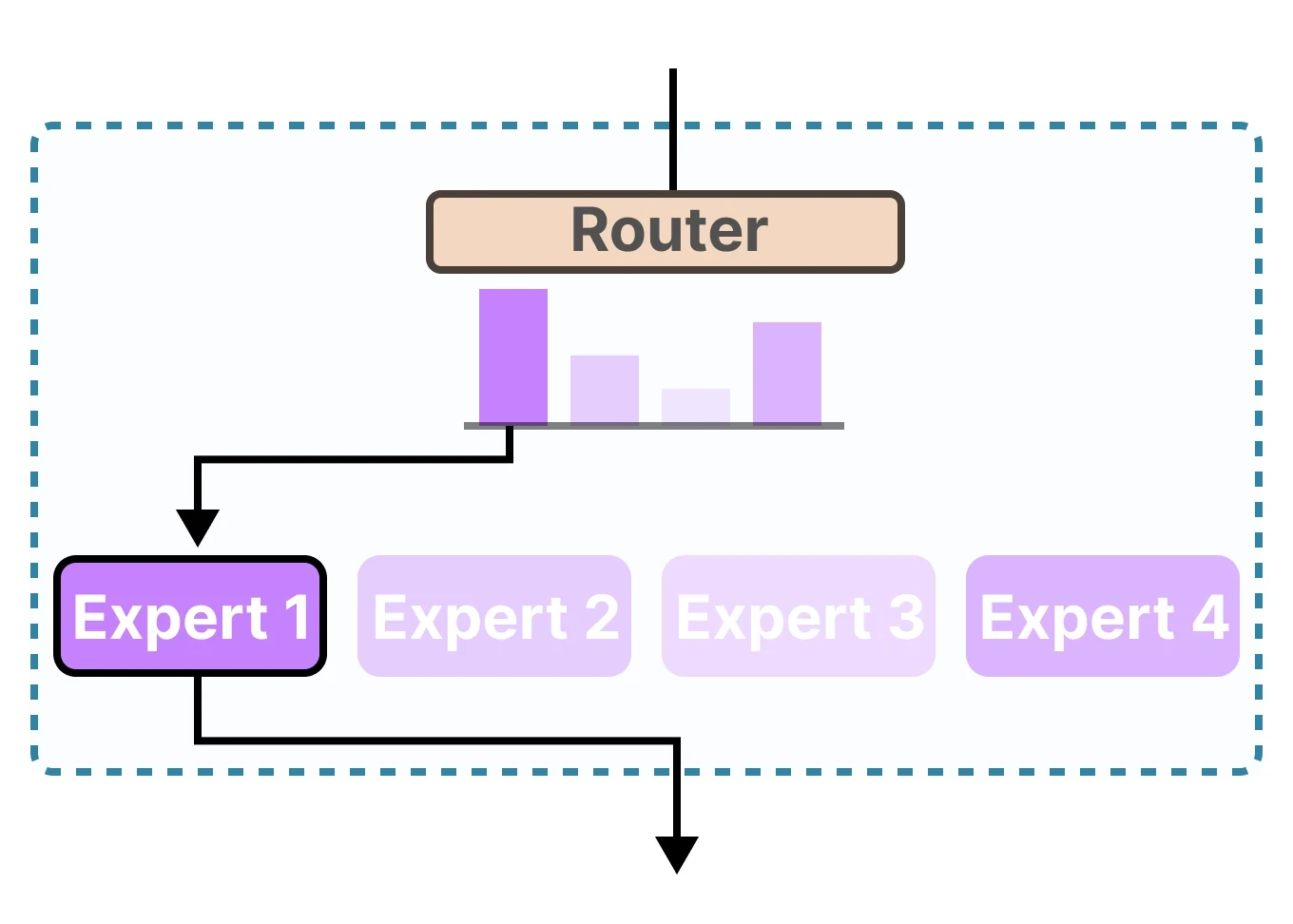
Hasilnya? Kita bisa memiliki kapasitas model yang masif (misalnya 21 miliar parameter) tetapi dengan biaya komputasi yang setara dengan model yang jauh lebih kecil selama fase inference. Ini sangat krusial untuk sentiment analysis skala besar di mana latency rendah adalah harga mati.
Mengapa Bahasa Indonesia Butuh Pendekatan Spesifik?
Mungkin kamu bertanya-tanya, "Kenapa tidak pakai model bahasa Inggris saja yang sudah canggih?". Bahasa Indonesia memiliki karakteristik unik yang tidak dimiliki bahasa Inggris. Kita punya variansi yang sangat lebar antara Bahasa Baku (seperti di berita Kompas atau Tempo) dan Bahasa Gaul atau bahasa "Alay" yang kita temukan di Twitter (X) dan Instagram.
Jika kita menggunakan model yang dilatih hanya pada teks bahasa Inggris, model tersebut tidak akan paham nuansa partikel seperti "lah", "sih", atau singkatan-singkatan kreatif netizen kita seperti "yg", "gk", atau "bgt". Inilah alasan mengapa kita menggunakan IndoBERT.
IndoBERT adalah varian BERT yang dilatih secara khusus menggunakan korpus Bahasa Indonesia yang sangat besar—sekitar 4 miliar token! Model ini memahami struktur morfologi bahasa kita dengan jauh lebih baik, mulai dari imbuhan hingga konteks budaya lokal.

Persiapan Lingkungan (Environment Setup)
Sebelum mulai menulis kode, pastikan kamu sudah menginstal library yang diperlukan. Buka terminal kamu dan jalankan perintah berikut:
pip install transformers torch datasets gradio pillow
Library transformers akan menjadi alat utama kita, sementara torch (PyTorch) akan bertindak sebagai engine di balik layarnya.
Cara Termudah: Menggunakan Pipeline
Hugging Face menyediakan abstraksi tingkat tinggi yang disebut pipeline. Ini adalah cara tercepat jika kamu ingin langsung melihat hasil tanpa harus pusing dengan detail arsitektur di awal.
from transformers import pipeline
# Memuat pipeline sentiment analysis dengan model default
classifier = pipeline("sentiment-analysis")
# Menguji dengan kalimat Bahasa Indonesia
res = classifier("Saya sangat senang belajar AI di CordivAI!")
print(res)
Namun, perlu diingat bahwa secara default, pipeline mungkin menggunakan model yang dilatih untuk Bahasa Inggris. Untuk hasil terbaik di Bahasa Indonesia, kita harus menentukan model spesifik.
Implementasi Mendalam: Tokenization dan Model Selection
Sekarang, mari kita masuk ke mode "Senior Engineer". Kita akan membedah proses ini langkah demi langkah menggunakan arsitektur AutoModel.
1. Tokenization: Menjembatani Teks dan Angka
Model AI tidak membaca teks seperti manusia; mereka membaca angka. Tokenizer bertugas memecah teks menjadi potongan-potongan kecil yang disebut token dan mengubahnya menjadi ID numerik.
from transformers import AutoTokenizer
model_name = "indobenchmark/indobert-base-p1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "Pelayanan toko ini sangat mengecewakan."
inputs = tokenizer(text, return_tensors="pt")
print(inputs)
Tokenizer IndoBERT menggunakan teknik subword tokenization. Artinya, jika ada kata yang tidak dikenal, ia akan memecahnya menjadi bagian-bagian yang lebih kecil (misalnya "mengecewakan" bisa jadi "mengecewa" + "##kan"). Ini sangat efektif untuk menangani kosakata yang luas.
2. Model Inference
Setelah teks menjadi angka, kita memasukkannya ke dalam model untuk mendapatkan skor mentah yang disebut logits.
from transformers import AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=3) # Positif, Negatif, Netral
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# Mengubah logits menjadi probabilitas menggunakan Softmax
probabilities = torch.nn.functional.softmax(logits, dim=-1)
print(probabilities)
Menangani Tantangan Riil: Dataset Tidak Seimbang
Dalam proyek dunia nyata, jarang sekali kita mendapatkan jumlah data yang seimbang antara sentimen positif dan negatif. Seringkali data negatif lebih sedikit (minoritas). Jika kita membiarkannya, model akan menjadi bias dan cenderung menebak kelas mayoritas.
Ada dua strategi canggih untuk mengatasi hal ini yang sering saya gunakan:
Strategi A: Back Translation (Data Augmentation)
Kita bisa menciptakan data sintetis baru untuk kelas minoritas dengan cara menerjemahkan teks tersebut ke bahasa lain (misal: Inggris atau Jerman), lalu menerjemahkannya kembali ke Bahasa Indonesia. Hasil akhirnya seringkali memiliki makna yang sama tetapi dengan pilihan kata yang berbeda.
def back_translation(text):
# Logika sederhana: ID -> EN -> ID
en_text = translate_id_to_en(text)
new_id_text = translate_en_to_id(en_text)
return new_id_text

Strategi B: Weighted Loss
Alih-alih menambah data, kita bisa mengubah cara model belajar. Kita memberikan "hukuman" (loss) yang lebih besar jika model salah menebak kelas minoritas. Dengan begitu, model dipaksa untuk lebih memperhatikan data yang sedikit tersebut.
import torch.nn as nn
from transformers import Trainer
class CustomTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.get("labels")
outputs = model(**inputs)
logits = outputs.get('logits')
# Memberikan bobot lebih tinggi pada kelas minoritas
weights = torch.tensor([1.0, 2.5, 1.0]) # Misal kelas negatif di indeks 1 diberi bobot 2.5
loss_fct = nn.CrossEntropyLoss(weight=weights.to(logits.device))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
Dari pengalaman saya, Weighted Loss seringkali lebih efisien secara komputasi karena kita tidak perlu melakukan proses translasi yang memakan waktu untuk ribuan baris data.
Deployment: Membuat Aplikasi Interaktif dengan Gradio
Model yang hebat tidak akan berguna jika hanya tersimpan di dalam file .pt di komputer kamu. Kita perlu membuatnya bisa diakses oleh orang lain. Gradio adalah Library yang sangat keren untuk membuat User Interface (UI) hanya dengan beberapa baris kode Python.
Berikut adalah kode lengkap untuk membuat aplikasi sentiment analysis kamu sendiri:
import gradio as gr
from transformers import pipeline
# Memuat model IndoBERT yang sudah difine-tune (sebagai contoh)
# Di sini kita menggunakan pipeline untuk kemudahan deployment
model_checkpoint = "indobenchmark/indobert-base-p1"
nlp_pipeline = pipeline("sentiment-analysis", model=model_checkpoint)
def analyze_sentiment(text):
results = nlp_pipeline(text)
label = results[0]['label']
score = results[0]['score']
return f"Hasil: {label} (Skor Keyakinan: {score:.4f})"
# Membuat antarmuka Gradio
interface = gr.Interface(
fn=analyze_sentiment,
inputs=gr.Textbox(lines=2, placeholder="Masukkan teks Bahasa Indonesia di sini..."),
outputs="text",
title="Indonesian Sentiment Analyzer v1.0",
description="Masukkan kalimat untuk mengetahui apakah sentimennya positif, negatif, atau netral."
)
if __name__ == "__main__":
interface.launch()
Setelah kamu menjalankan kode di atas, Gradio akan memberikan tautan lokal (dan opsional tautan publik) di mana kamu bisa mengetikkan kalimat dan melihat hasilnya secara instan! Kamu juga bisa meng-host aplikasi ini secara gratis di Hugging Face Spaces.
Alur Kerja Modern NLP (End-to-End Workflow)
Untuk merangkum apa yang telah kita pelajari, membangun model NLP modern untuk Bahasa Indonesia mengikuti alur kerja yang sangat terstruktur:
- Pengumpulan Data: Mengambil data dari media sosial atau ulasan produk.
- Preprocessing: Membersihkan teks, formalisasi kata alay, dan menangani emoji.
- Memilih Arsitektur: Menggunakan IndoBERT untuk pemahaman bahasa lokal yang superior.
- Menangani Imbalans: Menggunakan Weighted Loss untuk memastikan model adil terhadap semua kategori sentimen.
- Fine-Tuning: Melatih model pada dataset spesifik kamu (misalnya dataset SmSA).
- Deployment: Mempublikasikan model menggunakan Gradio dan Hugging Face Spaces.
Kesimpulan
Membangun model sentiment analysis untuk Bahasa Indonesia kini jauh lebih mudah berkat ekosistem Hugging Face. Kita tidak lagi perlu membangun arsitektur dari nol. Dengan memanfaatkan model pre-trained seperti IndoBERT dan teknik efisiensi seperti MoE, kita bisa fokus pada kualitas data dan penyelesaian masalah bisnis yang nyata.
Jangan takut untuk bereksperimen dengan parameter, mencoba berbagai metode augmentasi data, atau mencoba model-model terbaru yang ada di Hugging Face Hub. Dunia AI bergerak sangat cepat, dan cara terbaik untuk tetap relevan adalah dengan terus membangun!
Sudah siap membangun model sentiment analysis pertama kamu? Langsung saja buka Google Colab atau VS Code kamu dan mulai coding!
Referensi
- Hugging Face. (2026). Mixture of Experts (MoEs) in Transformers. Retrieved from https://huggingface.co/blog/moe-transformers
- IndoBenchmark. (2020). IndoBERT: Pre-training BERT for the Indonesian Language. Retrieved from https://github.com/indobenchmark/indonlp
- Ramasamy, M. K. (2025). Hands-On Tutorial: Sentiment Analysis with Transformers + Gradio. Retrieved from https://medium.com/@madhankarthik30/hands-on-tutorial-sentiment-analysis-with-transformers-gradio-deploy-on-hugging-face-c6a445c78a04
- Singh, V. (2024). Step-by-Step Guide to Sentiment Analysis with Hugging Face in Python. Retrieved from https://medium.com/@vikashsinghy2k/step-by-step-guide-to-sentiment-analysis-with-hugging-face-in-python-dce1afb9dc25
- Chko. (2025). Implementing a Hugging Face Model for Sentiment Analysis. Retrieved from https://medium.com/@chko/implementing-a-hugging-face-model-for-sentiment-analysis-24d91f04444b
- Hugging Face. (2026). Training and Fine-tuning for Sentiment Analysis. Retrieved from https://huggingface.co/docs/transformers/training