
Evolusi pesat Large Language Models (LLMs) dan model difusi telah membawa kapabilitas AI transformatif ke garis depan teknologi modern. Namun, skala masif dari model-model ini—yang seringkali terdiri dari miliaran parameters—menghadirkan hambatan besar bagi deployment lokal pada hardware kelas konsumen. Dalam konteks inilah, teknik quantization muncul sebagai "jembatan" kritis yang memungkinkan jaringan saraf raksasa ini masuk ke dalam batasan memori komputer pribadi, laptop, dan edge devices. Dengan secara strategis mengurangi presisi representasi numerik di dalam model, quantization mampu memangkas kebutuhan memori secara drastis dan mempercepat inference speeds, sekaligus mendemokratisasi akses terhadap high-performance AI.
Memahami Bottleneck Memori pada AI Modern
Tantangan utama dalam menjalankan model state-of-the-art seperti Llama, Gemma, atau Flux secara lokal adalah jumlah Video RAM (VRAM) atau system RAM yang sangat besar yang diperlukan untuk menyimpan parameters mereka. Setiap parameter dalam sebuah model bertindak sebagai "sinapsis" yang menyimpan pengetahuan yang telah dipelajari, yang biasanya direpresentasikan sebagai high-precision floating-point numbers.
Dalam kondisi aslinya setelah proses training, model seringkali menggunakan format Float32 (FP32), Float16 (FP16), atau BFloat16 (BF16). Sebagai gambaran teknis, sebuah model standar dengan 7 miliar parameters yang disimpan dalam presisi FP16 membutuhkan memori sekitar 14 Gigabytes (GB) hanya untuk menyimpan weights (7 miliar * 2 bytes/parameter). Angka ini belum memperhitungkan overhead tambahan untuk conversation context (yang disimpan dalam KV cache) serta kebutuhan sistem operasi. Model yang lebih masif, seperti FLUX.1-dev yang berukuran 31.4 GB, akan mustahil dijalankan pada hardware lokal tanpa optimasi khusus.

Mekanisme Quantization: Transformasi dari Floats ke Integers
Secara fundamental, quantization adalah bentuk canggih dari lossy compression yang dirancang khusus untuk neural networks. Tujuan utamanya adalah merepresentasikan nilai floating-point presisi tinggi dari model weights dengan format bit yang lebih rendah, seperti 8-bit atau 4-bit integers, tanpa mendegradasi kualitas output atau "kecerdasan" model secara signifikan.
Beberapa format quantized yang umum digunakan meliputi:
- INT8 (8-bit): Menggunakan hanya 1 byte per parameter, yang secara efektif memangkas memory footprint menjadi setengahnya dibandingkan dengan FP16. Format ini dianggap "nearly lossless" untuk sebagian besar aplikasi praktis.
- INT4 (4-bit): Menggunakan hanya setengah byte per parameter. Kompresi agresif ini dapat mengecilkan model berukuran 14 GB menjadi sekitar 3.5 GB, memungkinkannya berjalan pada hardware dengan VRAM sekecil 4-6 GB.
- FP8 (8-bit Floating Point): Format yang relatif baru yang mencoba mempertahankan dynamic range dari higher-precision floats sambil tetap menawarkan penghematan memori layaknya format 8-bit.
Proses quantization melibatkan lebih dari sekadar pembulatan angka sederhana. Algoritma canggih melakukan analisis terhadap distribusi weights di seluruh model dan menggunakan transformasi matematika untuk memetakan nilai asli ke dalam rentang terbatas dari format bit yang lebih rendah. Hal ini memastikan bahwa informasi yang paling "penting" tetap terjaga, sehingga meminimalkan apa yang disebut sebagai quantization error.
Deep Dive: Backend Quantization pada Hugging Face Diffusers
Untuk model pembuatan gambar seperti Flux, library Diffusers dari Hugging Face menyediakan beberapa specialized backends yang melayani kebutuhan hardware dan performa yang berbeda. Backends ini memungkinkan developer untuk melakukan quantization pada komponen spesifik dari pipeline, seperti Transformer (inti dari generative engine) dan T5 Text Encoder.
1. bitsandbytes (BnB)
Library bitsandbytes adalah pilar utama dalam ekosistem LLM, terutama bagi pengguna NVIDIA. BnB mendukung quantization 4-bit dan 8-bit, serta sering dipasangkan dengan NF4 (NormalFloat 4), sebuah data type yang dioptimalkan khusus untuk distribusi weights dalam neural networks yang terdistribusi secara normal. Dalam berbagai benchmarks, melakukan quantization pada model Flux-dev ke 4-bit menggunakan bitsandbytes berhasil mengurangi peak memory usage dari 36.1 GB menjadi hanya 17.2 GB.
2. torchao
torchao adalah library native dari PyTorch yang dirancang untuk optimasi arsitektur. Library ini mendukung format "weight-only" quantization seperti int8_weight_only dan int4_weight_only. Salah satu keunggulan utamanya adalah kompatibilitas dengan torch.compile, yang dapat meningkatkan inference speed secara signifikan dengan mengoptimalkan computational graph setelah proses quantization selesai.
3. Quanto
Dikembangkan sebagai bagian dari library Hugging Face Optimum, Quanto menyediakan toolkit quantization serbaguna yang dapat bekerja di berbagai platform hardware, termasuk CPU, GPU, dan MPS (Apple Silicon). Quanto mendukung presisi INT4, INT8, dan FP8, menawarkan solusi fleksibel bagi developer yang menargetkan lingkungan hardware di luar ekosistem NVIDIA.
4. GGUF
Format GGUF, yang dipopulerkan oleh komunitas llama.cpp, adalah container yang sangat efisien untuk quantized models. Format ini memungkinkan loading "single-file" dan sangat cocok untuk local inference pada CPU konsumen dan Apple Silicon. GGUF mendukung berbagai level quantization (misalnya, Q2_K, Q4_K_M, Q8_0), yang memungkinkan pengguna untuk menemukan keseimbangan ideal antara ukuran file dan akurasi model.
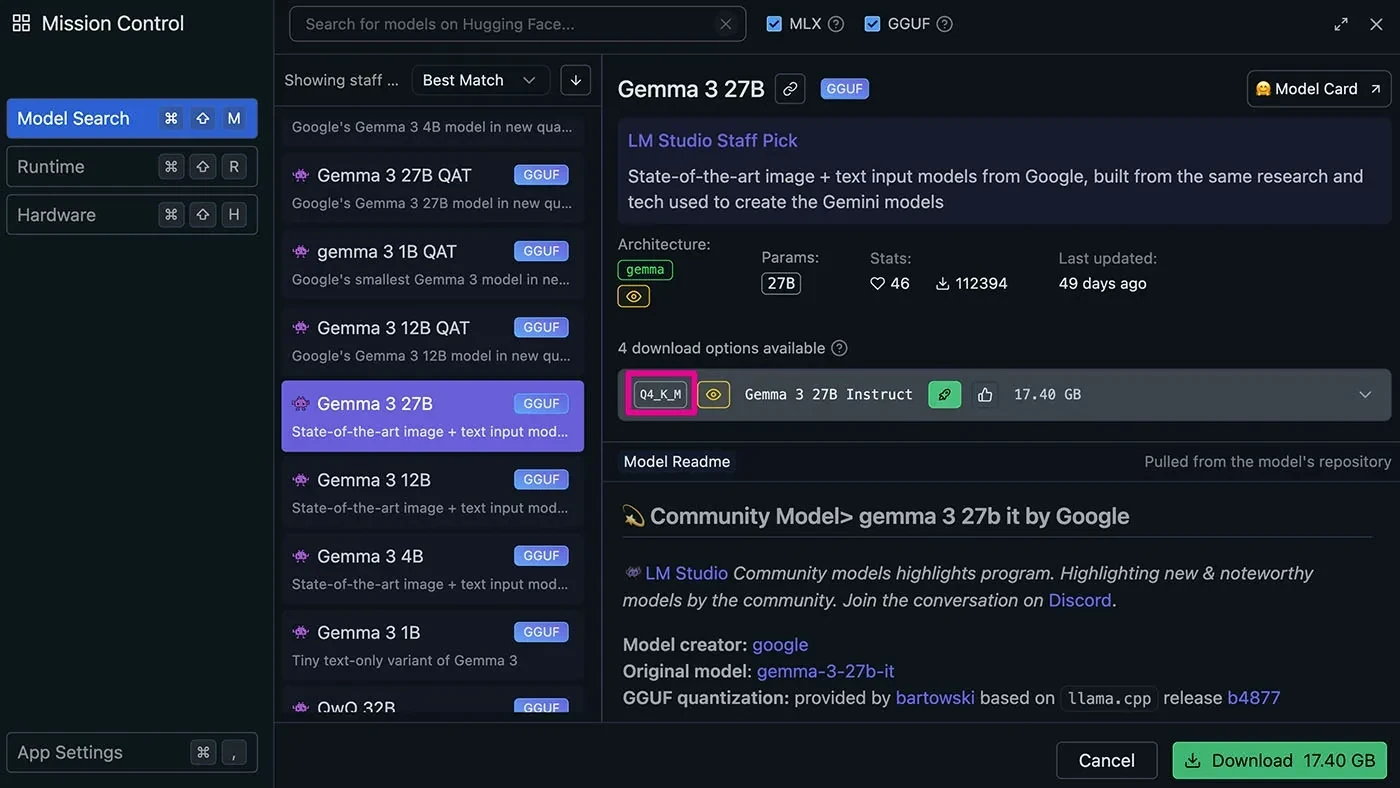
Lansekap Tooling Inference di Tahun 2026
Memasuki tahun 2026, ekosistem untuk local LLM inference telah berkembang dari sekadar hobi menjadi infrastruktur tingkat profesional yang kokoh. Software tools yang digunakan telah terkonsolidasi menjadi beberapa opsi berperforma tinggi, yang sebagian besar dibangun di atas llama.cpp, engine berbasis C++ yang mempelopori penggunaan quantization pada hardware konsumen.
Ollama: Standar bagi Developer
Ollama telah mengukuhkan posisinya sebagai "Docker-nya AI lokal." Kesederhanaannya—yang terlihat dari instalasi satu perintah dan manajemen model yang intuitif—menjadikannya pilihan default bagi para developer. Pada tahun 2026, Ollama telah memperluas kapabilitasnya dengan menyertakan dukungan native untuk image generation, integrasi web search, dan structured output. Yang paling krusial, OpenAI-compatible API miliknya memungkinkan Ollama berfungsi sebagai pengganti cloud-based backends dalam tumpukan software yang sudah ada.
LM Studio dan Alat Spesialis Lainnya
Bagi pengguna yang lebih menyukai antarmuka visual, LM Studio menyediakan pengalaman "model explorer" yang canggih. Pengguna dapat menjelajahi Hugging Face secara langsung, mengunduh model dengan satu klik, dan membandingkan berbagai versi quantized secara berdampingan. Alat lain yang patut diperhatikan adalah vLLM, yang dioptimalkan untuk production-grade GPU serving dengan continuous batching, serta Exo, yang memungkinkan "distributed inference"—menggabungkan kekuatan komputasi dari beberapa perangkat lokal (seperti beberapa Mac Minis atau iPhone) untuk menjalankan satu model besar.
Panduan Perangkat Keras: Efisiensi untuk Setiap Anggaran
Lansekap hardware pada tahun 2026 menawarkan jalur yang jelas bagi para antusias AI lokal. Memory bandwidth dan kapasitas (VRAM/Unified Memory) tetap menjadi metrik paling kritis untuk performa inference.
| Kategori | Rekomendasi Hardware | Estimasi Kemampuan |
|---|---|---|
| Best Value | Mac Mini M4 Pro (48GB Unified Memory) | Menjalankan model 14B - 30B dengan token-per-second tinggi. |
| Entry Level | RTX 4060 Ti (16GB VRAM) | Menangani model 7B - 8B dengan lancar untuk tugas asisten harian. |
| High End | Dual RTX 5090 / Mac Studio M4 Ultra | Deployment model "frontier-class" (70B+) sepenuhnya secara lokal. |
Bagi sebagian besar pengguna, Mac Mini M4 Pro dengan harga sekitar $1,999 dianggap sebagai "sweet spot" karena efisiensi energinya dan kapasitas memori yang cukup besar untuk menjalankan model menengah ke atas dengan performa yang sangat baik.
Riset Lanjutan: Melampaui Batas Quantization
Komunitas riset terus menemukan cara inovatif untuk memeras lebih banyak performa dari quantized models. Temuan terbaru dari konferensi seperti EMNLP 2024 dan NeurIPS 2024 menyoroti beberapa kemajuan kunci dalam mengatasi batasan teknis quantization tradisional.
Mengatasi Activation Outliers
Salah satu tantangan persisten dalam quantization adalah keberadaan "activation outliers"—nilai numerik spesifik yang jauh lebih besar daripada yang lain, yang menyebabkan quantization errors yang tinggi.
- CushionCache: Teknik ini memitigasi outliers dengan mencari set spesifik dari Key-Value (KV) caches untuk bertindak sebagai "prefix," yang meregulasi token-token berikutnya agar lebih ramah terhadap proses quantization.
- SmoothRot: Dengan menggunakan transformasi Hadamard dan channel-wise scaling, SmoothRot mengubah outliers ekstrem menjadi distribusi yang lebih seragam, sehingga mempersempit celah performa antara model 4-bit dan 16-bit.
Strategi Mixed-Precision dan Hybrid
Alih-alih menerapkan bit-depth yang sama ke seluruh model, strategi mixed-precision mengalokasikan lebih banyak bit ke bagian neural network yang paling "sensitif."
- QUIK: Strategi hybrid ini mengompresi sebagian besar weights dan activations ke 4-bit, namun tetap mempertahankan sebagian kecil "outlier weights" dalam presisi yang lebih tinggi. Hal ini menghasilkan peningkatan throughput hingga 3.4x dibandingkan dengan eksekusi FP16 penuh (Alistarh et al., 2024).
- Delta-CoMe: Dirancang untuk model yang telah melalui proses fine-tuning, metode ini mengompresi "delta weights" menggunakan mixed precision, menjaga performa spesifik tugas sambil secara signifikan mengurangi ukuran model (Ping et al., 2024).
Optimasi Bottleneck Lainnya: KV Cache dan Attention
Seiring dengan meluasnya context windows yang kini sering mencapai 128K tokens atau lebih, KV Cache (memori jangka pendek model) menjadi bottleneck memori utama yang harus diatasi.
Kompresi KV Cache
- Coupled Quantization (CQ): Metode ini melakukan quantization pada beberapa channels dari KV cache secara bersamaan (jointly), memanfaatkan informasi mutual antar channels untuk mencapai tingkat kompresi ekstrem (hingga 1-bit per channel) dengan kehilangan akurasi yang minimal.
- AnTKV: Dengan menggunakan "Anchor Score" untuk mengidentifikasi dan menjaga token yang paling sensitif dalam presisi penuh, AnTKV memungkinkan penggunaan context lengths yang jauh lebih panjang pada memori GPU yang terbatas.
FlashAttention-3
Iterasi terbaru dari mekanisme attention, FlashAttention-3, memanfaatkan fitur hardware-specific dari Hopper GPUs (seperti H100) dan dukungan low-precision FP8. Teknik ini mencapai pemanfaatan hingga 85% dari theoretical performance GPU, membuat proses "berpikir" inti dari LLMs menjadi jauh lebih cepat dan efisien (Shah et al., 2024).
Kesimpulan: Demokratisasi Frontier AI
Konvergensi antara software tools yang matang, hardware konsumen yang terspesialisasi, dan riset quantization yang agresif telah mengubah lanskap AI secara fundamental. Kita telah mencapai titik di mana riset seperti LittleBit mulai mengeksplorasi "sub-1-bit" quantization (misalnya, 0.1 bits per weight), yang menjanjikan kompresi yang lebih ekstrem di masa depan.
Bagi pengguna rata-rata, "sweet spot" saat ini tetap berada pada Q4_K_M (quantization 4-bit dengan medium-sized groups), yang memberikan keseimbangan hampir sempurna antara kecepatan, ukuran, dan kecerdasan. Kemampuan untuk menjalankan model seperti GLM-5 atau Llama-3.1 secara lokal memastikan bahwa pengguna dapat menjaga privasi data dan mengurangi ketergantungan pada penyedia cloud terpusat tanpa harus mengorbankan kualitas interaksi AI mereka.
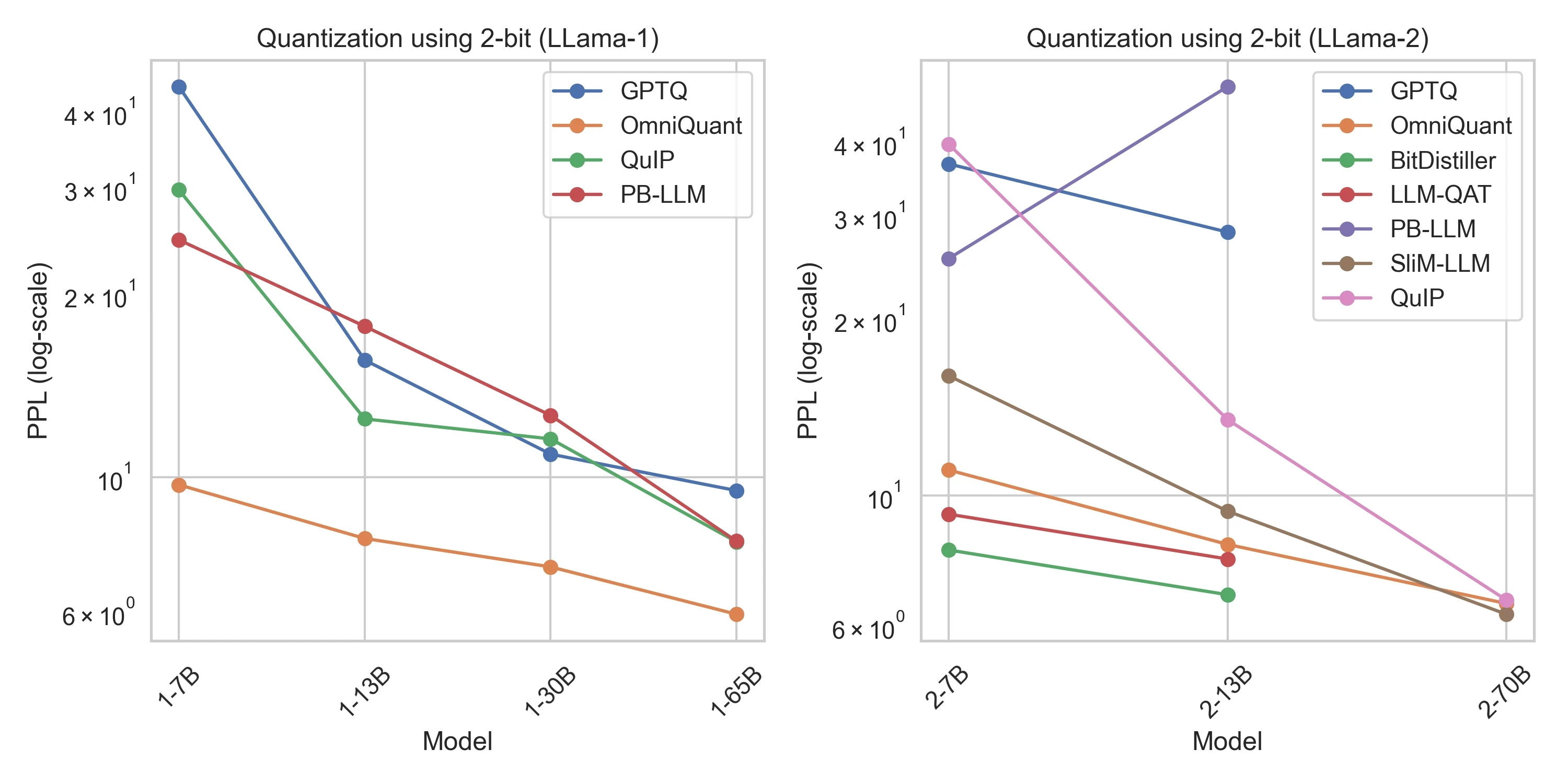
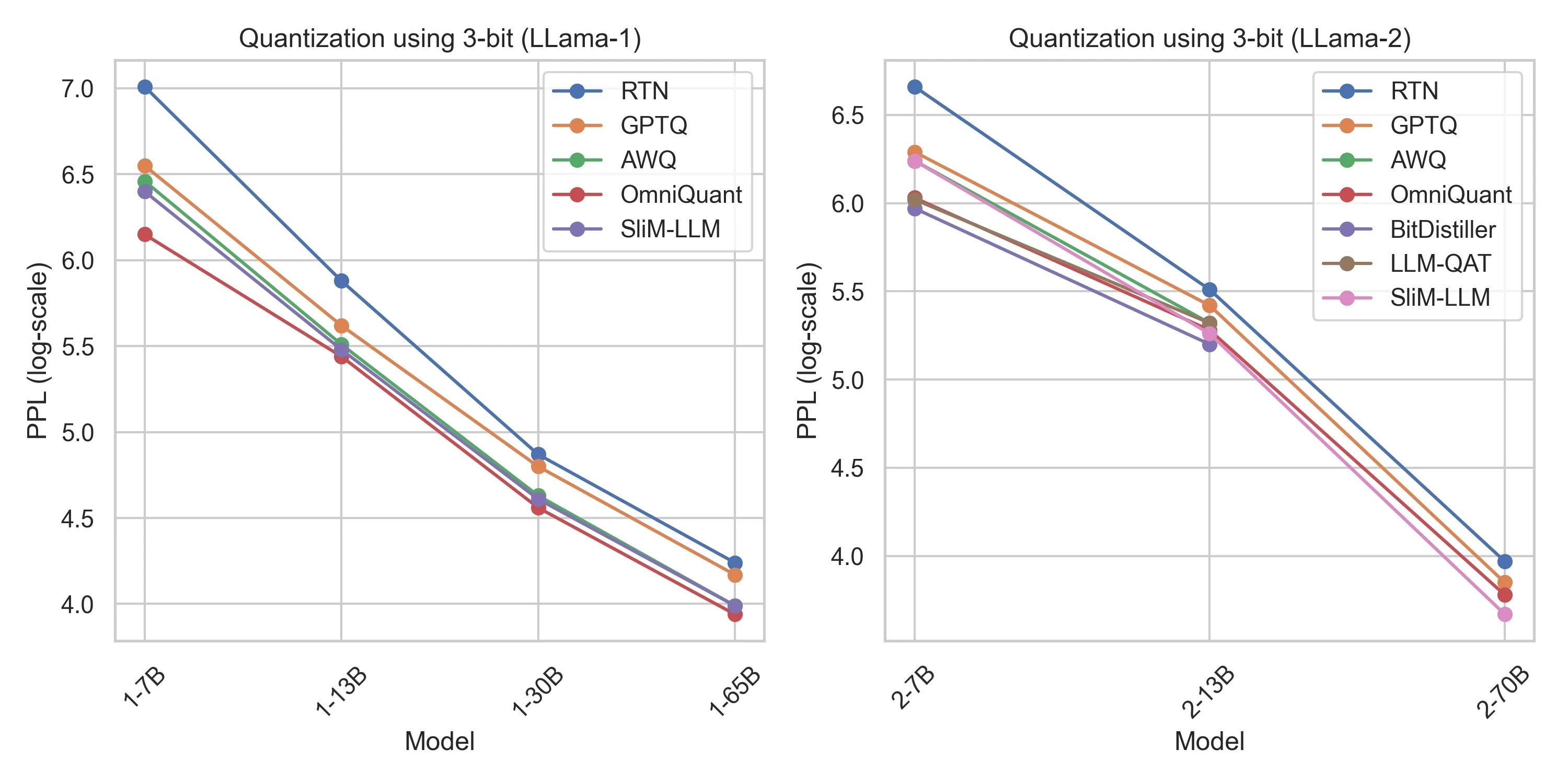
Referensi
Alistarh, D., et al. (2024). QUIK: 4-bit Weight and Activation Quantization. Proceedings of EMNLP 2024.
Boudro, D. (2026). Local LLM Inference in 2026: The Complete Guide to Tools, Hardware & Open-Weight Models. StarMorph Research. Retrieved from https://blog.starmorph.com/blog/local-llm-inference-tools-guide
Hugging Face. (2025). Exploring Quantization Backends in Diffusers. Retrieved from https://huggingface.co/blog/diffusers-quantization
Kurtic, E., et al. (2024). A Comprehensive Study on the Accuracy-Performance Trade-offs of LLM Quantization. Proceedings of NeurIPS 2024.
Liao, B., et al. (2024). ApiQ: Restoring Lost Information from Quantization via LoRA. Proceedings of EMNLP 2024.
Ping, B., et al. (2024). Delta-CoMe: Mixed-Precision Quantization for Delta Weights. Retrieved from https://github.com/thunlp/Delta-CoMe
Quantum Zeitgeist. (2026). Local LLM Inference on Edge Accelerators: Performance and Efficiency Analysis. Retrieved from https://quantumzeitgeist.com/local-llm-inference-on-edge-accelerators-performance-and-efficiency-analysis/
Schwarzmüller, M. (2026). Making Sense of Quantization. Retrieved from https://maximilian-schwarzmueller.com/articles/making-sense-of-quantization/
Shah, J., et al. (2024). FlashAttention-3: Fast and Accurate Attention with Low-Precision Floating Point. Proceedings of NeurIPS 2024.