Prediksi toksisitas molekul merupakan langkah krusial dalam penemuan obat (drug discovery) untuk mengurangi biaya dan waktu eksperimen laboratorium. Proyek ini mengimplementasikan model Deep Learning berbasis Long Short-Term Memory (LSTM) yang dikombinasikan dengan algoritma meta-heuristik Simulated Annealing (SA) untuk optimasi hyperparameters. Penggunaan LSTM sangat relevan karena data input berupa representasi SMILES yang bersifat sekuensial.
Metodologi
Metodologi proyek ini mencakup alur kerja dari data pre-processing hingga model tuning:
1. SMILES Processing: Mengubah urutan karakter kimia menjadi representasi numerik melalui tokenisasi dan vektorisasi.
2. Handling Imbalance: Menggunakan RandomOverSampler dari library imblearn karena dataset Tox21 memiliki ketidakseimbangan (imbalance dataset) kelas yang extreme.
3. Simulated Annealing Optimization: Algoritma SA digunakan sebagai hyperparameter tuning untuk mencari kombinasi hyperparameter terbaik antara jumlah unit LSTM, learning rate, dan batch size secara otomatis dengan meminimalkan fungsi loss pada data validasi.
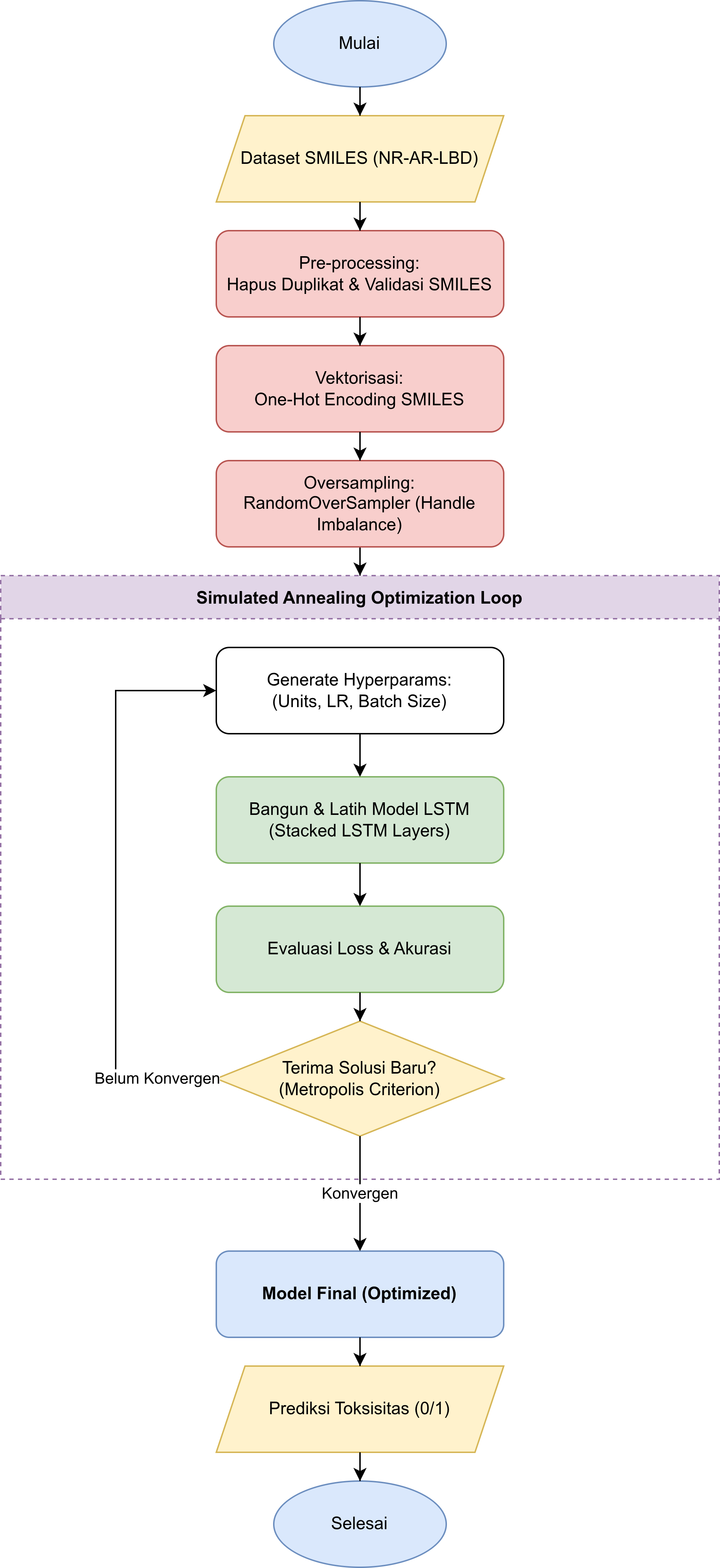
Model & Arsitektur
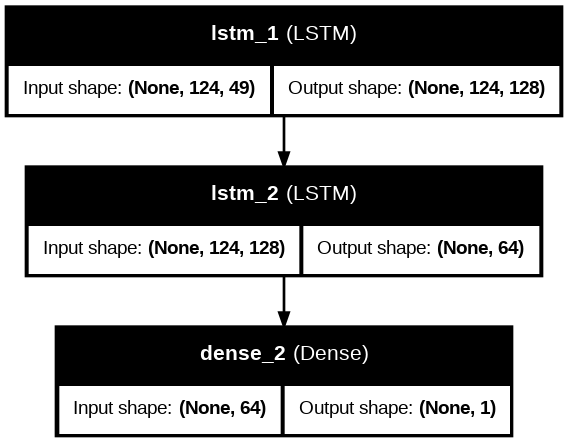
Arsitektur model dirancang dengan struktur Stacked LSTM:
- Input Layer: Menerima sekuens data molekul yang telah di-padding.
- LSTM Layers: Menggunakan dua lapisan LSTM dengan aktivasi ReLU. Berdasarkan optimasi SA, ditemukan bahwa 39 unit merupakan nilai optimal untuk menangkap pola kimiawi tanpa overfitting.
- Output Layer: Lapisan padat (Dense) dengan aktivasi Sigmoid untuk klasifikasi biner toksisitas.
Dataset
Dataset yang digunakan berasal dari Tox21 (Toxicology in the 21st Century), khususnya pada modul NR-AR-LBD (Androgen Receptor - Ligand Binding Domain).
- Jumlah Data: ~8.000 sampel molekul.
- Preprocessing: Pemotongan sekuens pada panjang maksimal (timesteps), penghapusan duplikat, dan sinkronisasi label.
Sampel data menunjukkan struktur molekul dalam format SMILES beserta target labelnya (0: Non-Toxic, 1: Toxic).
| SMILES | Label |
|---|---|
| Cl.CC(NCCC(C1=CC=CC=C1)C2=CC=CC=C2)C3=CC=CC=C3 | 0 |
| OC1=C([Hg]Cl)C=CC=C1 | 1 |
| FC(F)(F)S(=O)(=O)[N-]S(=O)(=O)C(F)(F)F.CCCCCCCCN+(CCCCCCCC)CCCCCCCC | 0 |
| COC1=CC=C(CCN2CCC(CC2)NC3=NC4=CC=CC=C4N3CC5=CC=C(F)C=C5)C=C1 | 0 |
| Cl.CCCOC1=C(Br)C(C)=C(S1)C(=O)N2CCC(CC2)C3=CC(CN)=CC=C3F | 1 |
| ... | ... |
| CCCC1=CC(=O)NC(=S)N1 | 0 |
| S=C1NCCN1 | 0 |
| S=C1NCCN1 | 0 |
| CCOP(=S)(OCC)OC1=CC=C(C=C1)N+=O | 0 |
| CCC(COC(=O)CCS)(COC(=O)CCS)COC(=O)CCS | 0 |
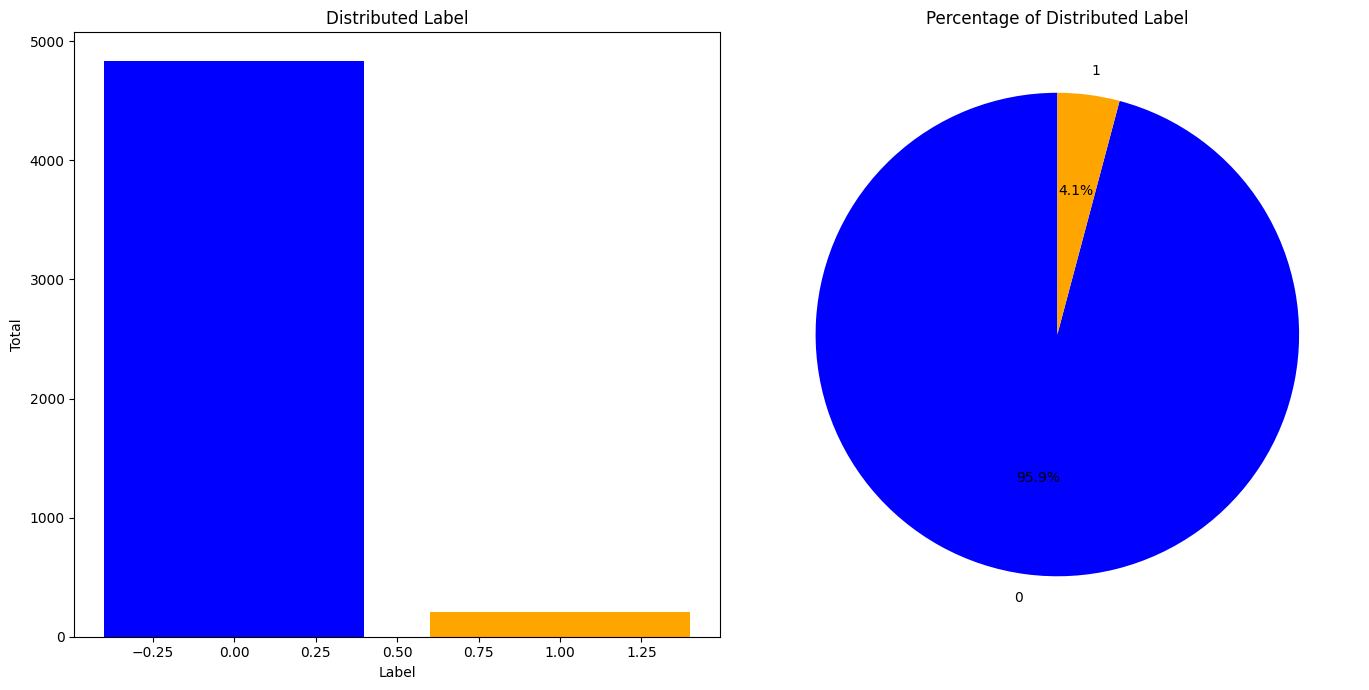
dataset ini sangat extreme imbalance karena memiliki jumlah data toxic lebih sedikit dibandingkan data non-toxic. Dengan label toxic hanya 167 dan non-toxic 3867 sampel. Oleh karena itu, digunakan RandomOverSampler untuk menyeimbangkan dataset.
Results
Model berhasil mencapai titik konvergensi yang stabil melalui pencarian Simulated Annealing.
- Best Parameters Found: units: 39, learning_rate: 0.0086, batch_size: 16.
- Best Loss: 0.6508
- Model menunjukkan kemampuan generalisasi yang baik pada data pengujian, mampu membedakan molekul toksik dengan tingkat presisi yang kompetitif dibandingkan metode klasifikasi tradisional.
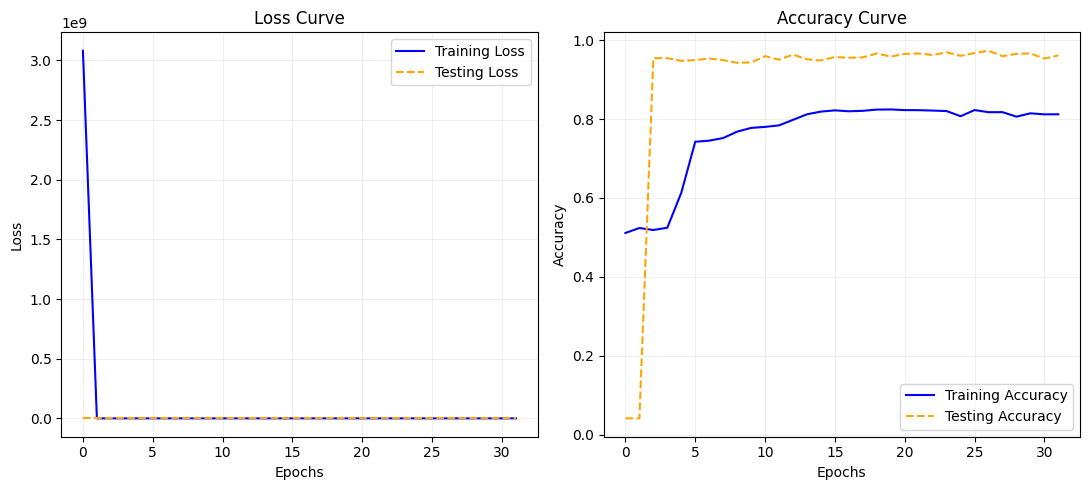
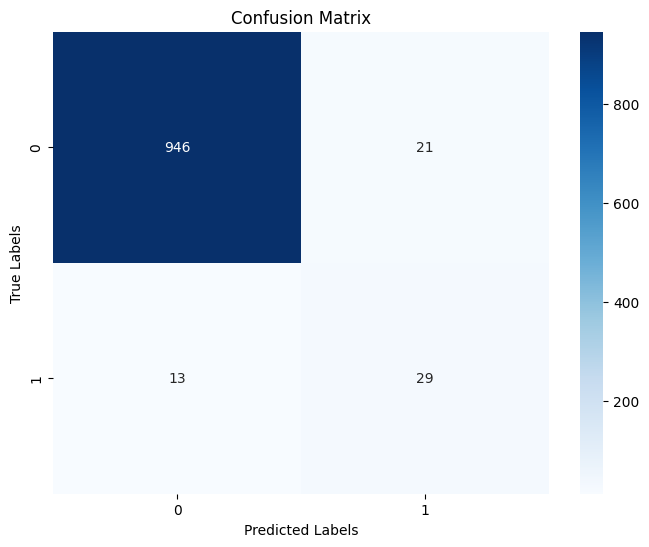
Berikut adalah visualisasi yang merepresentasikan performa konvergensi loss selama proses optimasi hiperparameter beserta evaluasi performa model:
Analisis Konvergensi & Metrik:
- Konvergensi Loss: Grafik pelatihan menunjukkan bahwa melalui Simulated Annealing, model berhasil menurunkan loss secara bertahap dan menghindari jebakan local minima. Tren penurunan pada training dan validation loss yang mulus mengindikasikan bahwa model telah mempelajari representasi token kimiawi dengan baik tanpa mengalami overfitting yang drastis.
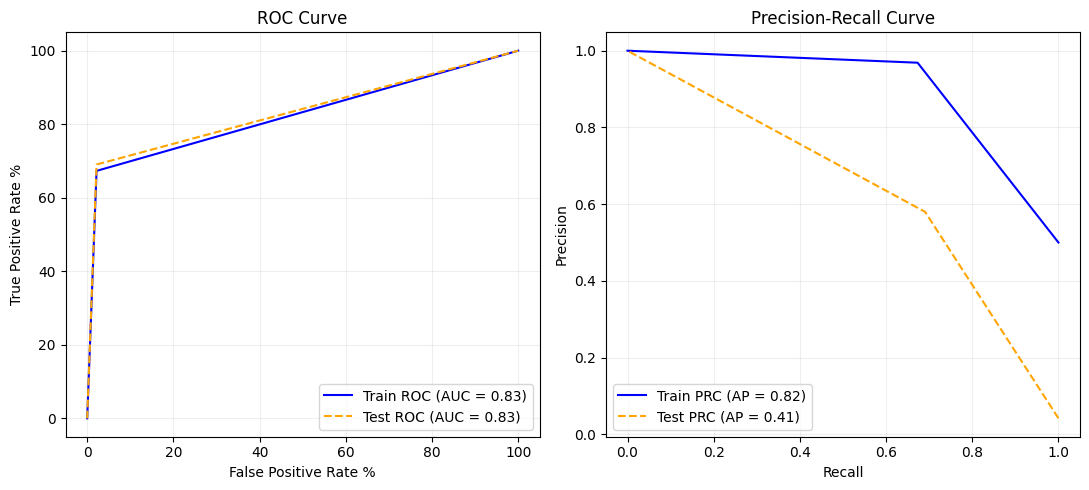
- Interpretasi Confusion Matrix: Pada data pengujian (test set), distribusi data dikembalikan ke kondisi alaminya yang sangat tidak seimbang (967 sampel kelas Non-Toxic berbanding 42 sampel kelas Toxic). Kendati demikian, Confusion Matrix mendemonstrasikan bahwa model tidak sekadar menebak kelas mayoritas. Model ini sanggup memberikan tingkat deteksi racun (Recall) sebesar ~69.05% dan kepastian prediksi racun (Precision) sebesar ~58.00%. Pencapaian ini sangat impresif mengingat jumlah sampel Toxic yang sangat minim (~4% dari total data uji), membuktikan bahwa arsitektur LSTM sukses mengekstraksi dan mengenali pola SMILES (Sequence) penyebab toksisitas.
Pada lapisan terakhir model, digunakan fungsi aktivasi Sigmoid yang mengonversi kalkulasi bobot hidden state menjadi skala probabilitas kontinu antara 0.0 hingga 1.0.
Prinsip Prediksi Probabilistik:
- Berdasarkan probabilitas tersebut, kita menerapkan threshold konvensional: Jika confidence score > 0.5, maka struktur SMILES kandidat molekul diklasifikasikan sebagai Toxic (1). Jika tidak, diprediksi sebagai Non-Toxic (0).
- Keuntungan dari output probabilistik ini pada industri farmasi atau riset penemuan obat (drug discovery) adalah peneliti dapat menganalisis senyawa dengan probabilitas borderline (contoh: 0.45 - 0.49). Hal ini memberi peringatan dini bagi molekul yang berpotensi memiliki toksisitas ringan sebelum uji klinis dilakukan, tidak sekadar memberikan keputusan hitam-putih.
Kesimpulan
Proyek ini berhasil mendemonstrasikan bahwa kombinasi arsitektur Stacked LSTM dengan algoritma optimasi Simulated Annealing (SA) sangat efektif untuk tugas prediksi toksisitas molekul (toxicity prediction) berbasis data SMILES. Penggunaan SA memungkinkan pencarian hyperparameter yang lebih cerdas dibandingkan grid search konvensional, menghasilkan model dengan performa optimal dalam waktu yang relatif efisien.
Secara keseluruhan, integrasi Deep Learning dengan algoritma meta-heuristik seperti Simulated Annealing membuka peluang besar dalam akselerasi computational drug discovery, khususnya dalam memfilter kandidat obat yang aman secara toksikologis.
Mau dibuatin juga?
Apakah kamu sedang mengerjakan tugas akhir, skripsi, atau riset publikasi di bidang Bioinformatika, Deep Learning, atau Optimasi Heuristik? Tenang, Cordivai bisa bgt kok bantuin kamu. Cordivai udah berpengalaman selama 5 tahun membantu berbagai macam riset mulai dari tugas, paper, skripsi, thesis, disertasi bahkan kami telah menerbitkan paper di jurnal internasional Q1.
Cordivai BUKAN kayak joki-joki yang cuma dibuatin terus ditinggal kok, kita juga bakal ngebimbing kamu, ngajarin kamu dan bahkan jadi temen diskusi untuk proyek-proyek kamu. Masalah harga, kita bisa nego-nego di whatsapp ya.
Project kamu juga mau kita bantu? Ngobrol yuk. Walaupun belum bisa jadi client kita, seenggaknya kamu bisa jadi temen kita.